Data Science introduction
Contents
%%html
<!-- The customized css for the slides -->
<link rel="stylesheet" type="text/css" href="../../assets/styles/basic.css"/>
<link rel="stylesheet" type="text/css" href="../../assets/styles/python-programming-basic.css"/>
43.4. Data Science introduction#
43.4.1. 1. Defining data science#
43.4.1.1. What’s Data Science#
Data Science is defined as a scientific field that uses scientific methods to extract knowledge and insights from structured and unstructured data, and apply knowledge and actionable insights from data across a broad range of application domains.
Main goal - extract knowledge from data.
Uses scientific methods, such as probability and statistics.
Obtained knowledge should be applied to produce some actionable insights.
Should be able to operate on both structured and unstructured data.
Application domain is important, and some degree of expertise in the problem domain is required.
43.4.1.2. What you can do with data#
Data acquisition.
Data storage.
A relational database.
A NoSQL database.
Data Lake.
Data processing.
Visualization / human insights.
Training a predictive model.
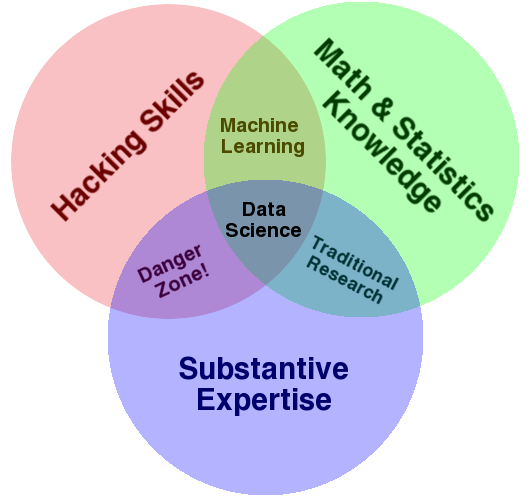 The data science venn diagram[1]
The data science venn diagram[1]
1. The data science venn diagram. URL: http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram (visited on 2022-08-27).
43.4.1.4. What you can do with data#
Data acquisition
Data storage
Data processing
Visualization / human insights
Training a predictive model
43.4.2. 2. Data Science ethics#
Data ethics
Applied ethics
Ethics culture
43.4.2.1. Basic definition#
Data ethics is a new branch of ethics that “studies and evaluates moral problems related to data, algorithms and corresponding practices”.
Applied ethics is the practical application of moral considerations. It’s the process of actively investigating ethical issues in the context of real-world actions, products, and processes, and taking corrective measures
Ethics culture is about operationalizing applied ethics to make sure that our ethical principles and practices are adopted in a consistent and scalable manner across the entire organization.
43.4.2.2. Ethics concepts#
Accountability
Transparency
Fairness
Reliability & Safety
Privacy & Security
Inclusiveness
 Responsible AI at Microsoft[1]
Responsible AI at Microsoft[1]
1. jcodella. Ethics and responsible use - personalizer - azure cognitive services. URL: https://learn.microsoft.com/en-us/azure/cognitive-services/personalizer/ethics-responsible-use (visited on 2022-10-01).
Accountability makes practitioners responsible for their data & AI operations, and compliance with these ethical principles.
Transparency ensures that data and AI actions are understandable (interpretable) to users, explaining the what and why behind decisions.
Fairness - focuses on ensuring AI treats all people fairly, addressing any systemic or implicit socio-technical biases in data and systems.
Reliability & Safety - ensures that AI behaves consistently with defined values, minimizing potential harms or unintended consequences.
Privacy & Security - is about understanding data lineage, and providing data privacy and related protections to users.
Inclusiveness - is about designing AI solutions with intention, and adapting them to meet a broad range of human needs & capabilities.
43.4.2.3. Ethics challenges#
Data ownership
Informed consent
Intellectual property
Data privacy
Right to be forgotten
Dataset bias
Data quality
Algorithm fairness
Misrepresentation
Free choice
Ethics Challenge |
Case Study |
|---|---|
Informed consent |
1972 - Tuskegee Syphilis Study - African American men who participated in the study were promised free medical care but deceived by researchers who failed to inform subjects of their diagnosis or about availability of treatment. Many subjects died & partners or children were affected; the study lasted 40 years. |
Data privacy |
2007 - The Netflix data prize provided researchers with 10M anonymized movie rankings from 50K customers to help improve recommendation algorithms. However, researchers were able to correlate anonymized data with personally-identifiable data in external datasets (e.g., IMDb comments) - effectively “de-anonymizing” some Netflix subscribers. |
Collection bias |
2013 - The City of Boston developed Street Bump, an app that let citizens report potholes, giving the city better roadway data to find and fix issues. However, people in lower income groups had less access to cars and phones, making their roadway issues invisible in this app. Developers worked with academics to equitable access and digital divides issues for fairness. |
Algorithmic fairness |
2018 - The MIT Gender Shades Study evaluated the accuracy of gender classification AI products, exposing gaps in accuracy for women and persons of color. A 2019 Apple Card seemed to offer less credit to women than men. Both illustrated issues in algorithmic bias leading to socio-economic harms. |
Data misrepresentation |
2020 - The Georgia Department of Public Health released COVID-19 charts that appeared to mislead citizens about trends in confirmed cases with non-chronological ordering on the x-axis. This illustrates misrepresentation through visualization tricks. |
Illusion of free choice |
2020 - Learning app ABCmouse paid $10M to settle an FTC complaint where parents were trapped into paying for subscriptions they couldn’t cancel. This illustrates dark patterns in choice architectures, where users were nudged towards potentially harmful choices. |
Data privacy & user rights |
2021 - Facebook Data Breach exposed data from 530M users, resulting in a $5B settlement to the FTC. It however refused to notify users of the breach violating user rights around data transparency and access. |
43.4.2.4. Applied ethics#
Professional codes, e.g.
Oxford Munich Code of Ethics
Data Science Association Code of Conduct (created 2013)
ACM Code of Ethics and Professional Conduct (since 1993)
Ethics checklists, e.g.
Deon - a general-purpose data ethics checklist
43.4.3. 3. Defining data#
Quantitative data
Qualitative data
Structured data - IoT, surveys, analysis of behavior
Unstructured data - texts, images or videos, logs
Semi-structured data - social network
43.4.4. 4. Introduction to statistics and probability#
43.4.4.1. Probability and random variables#
Probability is a number between 0 and 1 that expresses how probable an event is. And when we talk about events, we use random variables.
43.4.4.2. Aggregations: min, max, and everything in between#
Often when faced with a large amount of data, a first step is to compute summary statistics for the data in question.