Text Preprocessing
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet pandas scikit-learn numpy matplotlib jupyterlab_myst ipython nltk
30.7.1. Text Preprocessing#
Preprocessing in NLP is a means to get text data ready for further processing or analysis. Most of the time, preprocessing is a mix of cleaning and normalising techniques that make the text easier to use for the task at hand.
A useful library for processing text in Python is the Natural Language Toolkit (NLTK). This chapter will go into 6 of the most commonly used pre-processing steps and provide code examples so you can start using the techniques immediately.
30.7.1.1. Common NLTK preprocessing steps#
30.7.1.1.1. Tokenization#
Splitting the text into individual words or subwords (tokens).
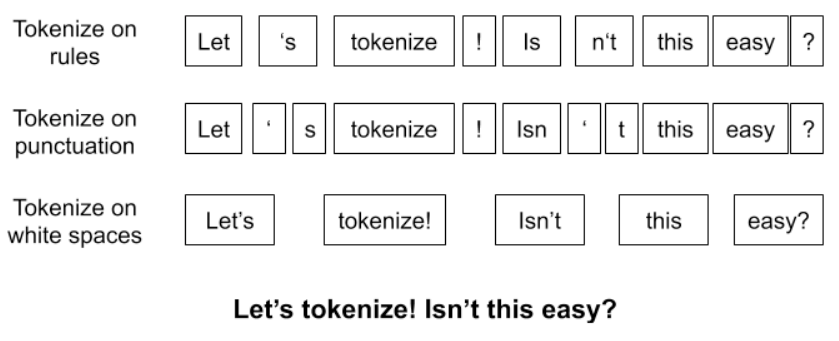
Fig. 30.1 Tokenization in NLP#
Here is how to implement tokenization in NLTK:
import nltk
# input text
text = "Natural language processing is a field of artificial intelligence that deals with the interaction between computers and human (natural) language."
# tokenize the text
tokens = nltk.word_tokenize(text)
print("Tokens:", tokens)
Tokens: ['Natural', 'language', 'processing', 'is', 'a', 'field', 'of', 'artificial', 'intelligence', 'that', 'deals', 'with', 'the', 'interaction', 'between', 'computers', 'and', 'human', '(', 'natural', ')', 'language', '.']
30.7.1.1.2. Remove stop words#
Removing common words that do not add significant meaning to the text, such as “a,” “an,” and “the.”
To remove common stop words from a list of tokens using NLTK, you can use the nltk.corpus.stopwords.words() function to get a list of stopwords in a specific language and filter the tokens using this list. Here is an example of how to do this:
import nltk
# input text
text = "Natural language processing is a field of artificial intelligence that deals with the interaction between computers and human (natural) language."
# tokenize the text
tokens = nltk.word_tokenize(text)
# get list of stopwords in English
stopwords = nltk.corpus.stopwords.words("english")
# remove stopwords
filtered_tokens = [token for token in tokens if token.lower() not in stopwords]
print("Tokens without stopwords:", filtered_tokens)
Tokens without stopwords: ['Natural', 'language', 'processing', 'field', 'artificial', 'intelligence', 'deals', 'interaction', 'computers', 'human', '(', 'natural', ')', 'language', '.']
30.7.1.1.3. Stemming#
Reducing words to their root form by removing suffixes and prefixes, such as converting “jumping” to “jump.” But it may produce non-existent words.

Fig. 30.2 Stemming in NLP#
To perform stemming on a list of tokens using NLTK, you can use the nltk.stem.WordNetLemmatizer() function to create a stemmer object and the method to stem each token. Here is an example of how to do this:
import nltk
# input text
text = "Natural language processing is a field of artificial intelligence that deals with the interaction between computers and human (natural) language."
# tokenize the text
tokens = nltk.word_tokenize(text)
# create stemmer object
stemmer = nltk.stem.PorterStemmer()
# stem each token
stemmed_tokens = [stemmer.stem(token) for token in tokens]
print("Stemmed tokens:", stemmed_tokens)
Stemmed tokens: ['natur', 'languag', 'process', 'is', 'a', 'field', 'of', 'artifici', 'intellig', 'that', 'deal', 'with', 'the', 'interact', 'between', 'comput', 'and', 'human', '(', 'natur', ')', 'languag', '.']
30.7.1.1.4. Lemmatization#
Reducing words to their base form by considering the context in which they are used, such as “running” or “ran” becoming “run”. This technique is similar to stemming, but it is more accurate as it considers the context of the word.
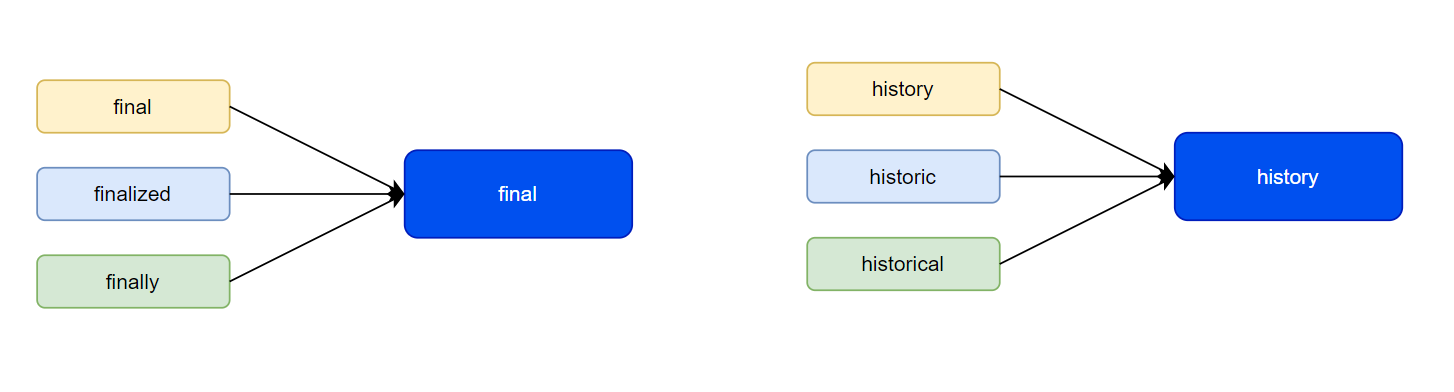
Fig. 30.3 Lemmatization in NLP#
To perform lemmatization on a list of tokens using NLTK, you can use the nltk.stem.WordNetLemmatizer() function to create a lemmatizer object and the lemmatize() method to lemmatize each token. Here is an example of how to do this:
import nltk
# input text
text = "Natural language processing is a field of artificial intelligence that deals with the interaction between computers and human (natural) language."
# tokenize the text
tokens = nltk.word_tokenize(text)
# create lemmatizer object
lemmatizer = nltk.stem.WordNetLemmatizer()
# lemmatize each token
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in tokens]
print("Lemmatized tokens:", lemmatized_tokens)
Lemmatized tokens: ['Natural', 'language', 'processing', 'is', 'a', 'field', 'of', 'artificial', 'intelligence', 'that', 'deal', 'with', 'the', 'interaction', 'between', 'computer', 'and', 'human', '(', 'natural', ')', 'language', '.']
30.7.1.1.5. Part Of Speech Tagging#
Identifying the part of speech of each word in the text, such as noun, verb, or adjective.

Fig. 30.4 POS tag and description#
To perform part of speech (POS) tagging on a list of tokens using NLTK, you can use the nltk.pos_tag() function to tag the tokens with their corresponding POS tags. Here is an example of how to do this:
import nltk
# input text
text = "Natural language processing is a field of artificial intelligence that deals with the interaction between computers and human (natural) language."
# tokenize the text
tokens = nltk.word_tokenize(text)
# tag the tokens with their POS tags
tagged_tokens = nltk.pos_tag(tokens)
print("Tagged tokens:", tagged_tokens)
Tagged tokens: [('Natural', 'JJ'), ('language', 'NN'), ('processing', 'NN'), ('is', 'VBZ'), ('a', 'DT'), ('field', 'NN'), ('of', 'IN'), ('artificial', 'JJ'), ('intelligence', 'NN'), ('that', 'IN'), ('deals', 'NNS'), ('with', 'IN'), ('the', 'DT'), ('interaction', 'NN'), ('between', 'IN'), ('computers', 'NNS'), ('and', 'CC'), ('human', 'JJ'), ('(', '('), ('natural', 'JJ'), (')', ')'), ('language', 'NN'), ('.', '.')]
30.7.1.1.6. Named Entity Recognition(NER)#
Extracting named entities from a text, like a person’s name.

Fig. 30.5 ner in NLP#
To perform named entity recognition (NER) on a list of tokens using NLTK, you can use the nltk.ne_chunk() function to identify and label named entities in the tokens. Here is an example of how to do this:
import nltk
# input text
text = "Natural language processing is a field of artificial intelligence that deals with the interaction between computers and human (natural) language. John Smith works at Google in New York."
# tokenize the text
tokens = nltk.word_tokenize(text)
# tag the tokens with their part of speech
tagged_tokens = nltk.pos_tag(tokens)
# identify named entities
named_entities = nltk.ne_chunk(tagged_tokens)
print("Named entities:", named_entities)
Named entities: (S
Natural/JJ
language/NN
processing/NN
is/VBZ
a/DT
field/NN
of/IN
artificial/JJ
intelligence/NN
that/IN
deals/NNS
with/IN
the/DT
interaction/NN
between/IN
computers/NNS
and/CC
human/JJ
(/(
natural/JJ
)/)
language/NN
./.
(PERSON John/NNP Smith/NNP)
works/VBZ
at/IN
(ORGANIZATION Google/NNP)
in/IN
(GPE New/NNP York/NNP)
./.)
30.7.1.2. NLTK preprocessing pipeline example#
Preprocessing techniques can be applied independently or in combination, depending on the specific requirements of the task at hand.
Here is an example of a typical NLP pipeline using the NLTK:
1.Tokenization: First, we need to split the input text into individual words (tokens). This can be done using the nltk.word_tokenize() function.
2.Part-of-speech tagging: Next, we can use the nltk.pos_tag() function to assign a part-of-speech (POS) tag to each token, which indicates its role in a sentence (e.g., noun, verb, adjective).
3.Named entity recognition: Using the nltk.ne_chunk() function, we can identify named entities (e.g., person, organization, location) in the text.
4.Lemmatization: We can use the nltk.WordNetLemmatizer() function to convert each token to its base form (lemma), which helps with the analysis of the text.
5.Stopword removal: We can use the nltk.corpus.stopwords.words() function to remove common words (stopwords) that do not add significant meaning to the text, such as “the,” “a,” and “an.”
6.Text classification: Finally, we can use the processed text to train a classifier using machine learning algorithms to perform tasks such as sentiment analysis or spam detection.
30.7.1.3. NLTK preprocessing example code#
First, we preprocess the text, including tokenization, part-of-speech tagging, named entity recognition, lemmatization and stopword removal.
import nltk
# input text
text = "Natural language processing is a field of artificial intelligence that deals with the interaction between computers and human (natural) language."
# tokenization
tokens = nltk.word_tokenize(text)
# part-of-speech tagging
pos_tags = nltk.pos_tag(tokens)
# named entity recognition
named_entities = nltk.ne_chunk(pos_tags)
# lemmatization
lemmatizer = nltk.WordNetLemmatizer()
lemmas = [lemmatizer.lemmatize(token) for token in tokens]
# stopword removal
stopwords = nltk.corpus.stopwords.words("english")
filtered_tokens = [token for token in tokens if token not in stopwords]
Then we do the text classification (example using a simple Naive Bayes classifier).
from nltk.classify import NaiveBayesClassifier
# training data (using a toy dataset for illustration purposes)
training_data = [("I enjoy the book.", "pos"),("I like this movie.", "pos"),("It was a boring movie.", "neg")]
# extract features from the training data
def extract_features(text):
features = {}
for word in nltk.word_tokenize(text):
features[word] = True
return features
# create a list of feature sets and labels
feature_sets = [(extract_features(text), label) for (text, label) in training_data]
# train the classifier
classifier = NaiveBayesClassifier.train(feature_sets)
# test the classifier on a new example
test_text = "I enjoyed the movie."
print("Sentiment:", classifier.classify(extract_features(test_text)))
Sentiment: pos
30.7.1.4. Your turn! 🚀#
Assignment - Beginner Guide to Text Pre-Processing
30.7.1.5. Acknowledgments#
Thanks to Neri Van Otten for creating the open-source project Top 14 Steps To Build A Complete NLTK Preprocessing Pipeline In Python.It inspire the majority of the content in this chapter.