Bagging
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet seaborn pandas scikit-learn numpy matplotlib jupyterlab_myst ipython
15.2. Bagging#
15.2.1. Bootstrapping#
Bagging (also known as Bootstrap aggregation) is one of the first and most basic ensemble techniques. It was proposed by Leo Breiman in 1994. Bagging is based on the statistical method of bootstrapping, which makes the evaluation of many statistics of complex models feasible.
The bootstrap method goes as follows. Let there be a sample \(\large X\) of size \(\large N\). We can make a new sample from the original sample by drawing \(\large N\) elements from the latter randomly and uniformly, with replacement. In other words, we select a random element from the original sample of size \(\large N\) and do this \(\large N\) times. All elements are equally likely to be selected, thus each element is drawn with the equal probability \(\large \frac{1}{N}\).
Let’s say we are drawing balls from a bag one at a time. At each step, the selected ball is put back into the bag so that the next selection is made equiprobably i.e. from the same number of balls \(\large N\). Note that, because we put the balls back, there may be duplicates in the new sample. Let’s call this new sample \(\large X_1\).
By repeating this procedure \(\large M\) times, we create \(\large M\) bootstrap samples \(\large X_1, \dots, X_M\). In the end, we have a sufficient number of samples and can compute various statistics of the original distribution.
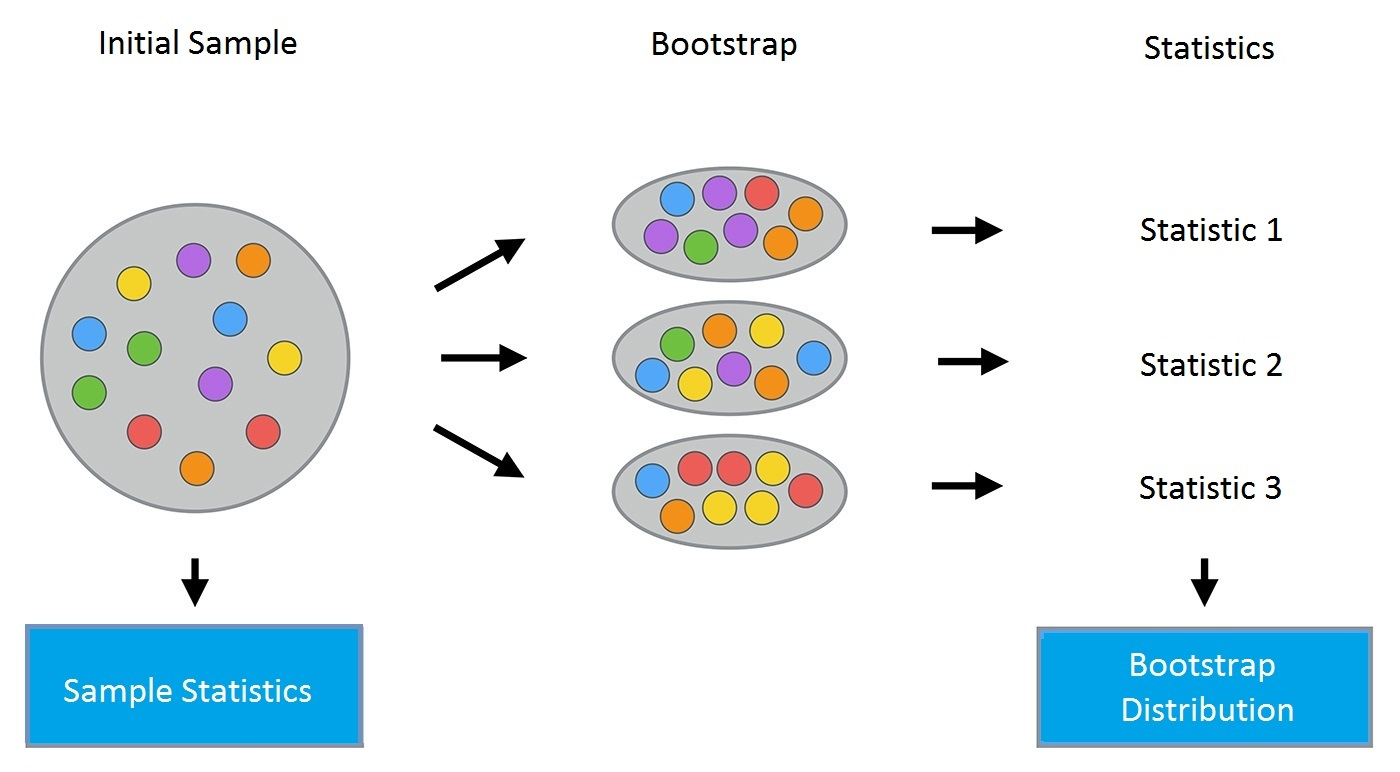
Fig. 15.2 Process of bootstrap#
For our example, we’ll use the familiar telecom_churn dataset. Previously, when we discussed feature importance, we saw that one of the most important features in this dataset is the number of calls to customer service. Let’s visualize the data and look at the distribution of this feature.
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
# Graphics in retina format are more sharp and legible
%config InlineBackend.figure_format = 'retina'
telecom_data = pd.read_csv("https://static-1300131294.cos.ap-shanghai.myqcloud.com/data/telecom_churn.csv")
telecom_data.head()
| State | Account length | Area code | International plan | Voice mail plan | Number vmail messages | Total day minutes | Total day calls | Total day charge | Total eve minutes | Total eve calls | Total eve charge | Total night minutes | Total night calls | Total night charge | Total intl minutes | Total intl calls | Total intl charge | Customer service calls | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | KS | 128 | 415 | No | Yes | 25 | 265.1 | 110 | 45.07 | 197.4 | 99 | 16.78 | 244.7 | 91 | 11.01 | 10.0 | 3 | 2.70 | 1 | False |
| 1 | OH | 107 | 415 | No | Yes | 26 | 161.6 | 123 | 27.47 | 195.5 | 103 | 16.62 | 254.4 | 103 | 11.45 | 13.7 | 3 | 3.70 | 1 | False |
| 2 | NJ | 137 | 415 | No | No | 0 | 243.4 | 114 | 41.38 | 121.2 | 110 | 10.30 | 162.6 | 104 | 7.32 | 12.2 | 5 | 3.29 | 0 | False |
| 3 | OH | 84 | 408 | Yes | No | 0 | 299.4 | 71 | 50.90 | 61.9 | 88 | 5.26 | 196.9 | 89 | 8.86 | 6.6 | 7 | 1.78 | 2 | False |
| 4 | OK | 75 | 415 | Yes | No | 0 | 166.7 | 113 | 28.34 | 148.3 | 122 | 12.61 | 186.9 | 121 | 8.41 | 10.1 | 3 | 2.73 | 3 | False |
telecom_data.loc[telecom_data["Churn"] == False, "Customer service calls"].hist(
label="Loyal"
)
telecom_data.loc[telecom_data["Churn"] == True, "Customer service calls"].hist(
label="Churn"
)
plt.xlabel("Number of calls")
plt.ylabel("Density")
plt.legend()
<matplotlib.legend.Legend at 0x7f1ada8a3220>
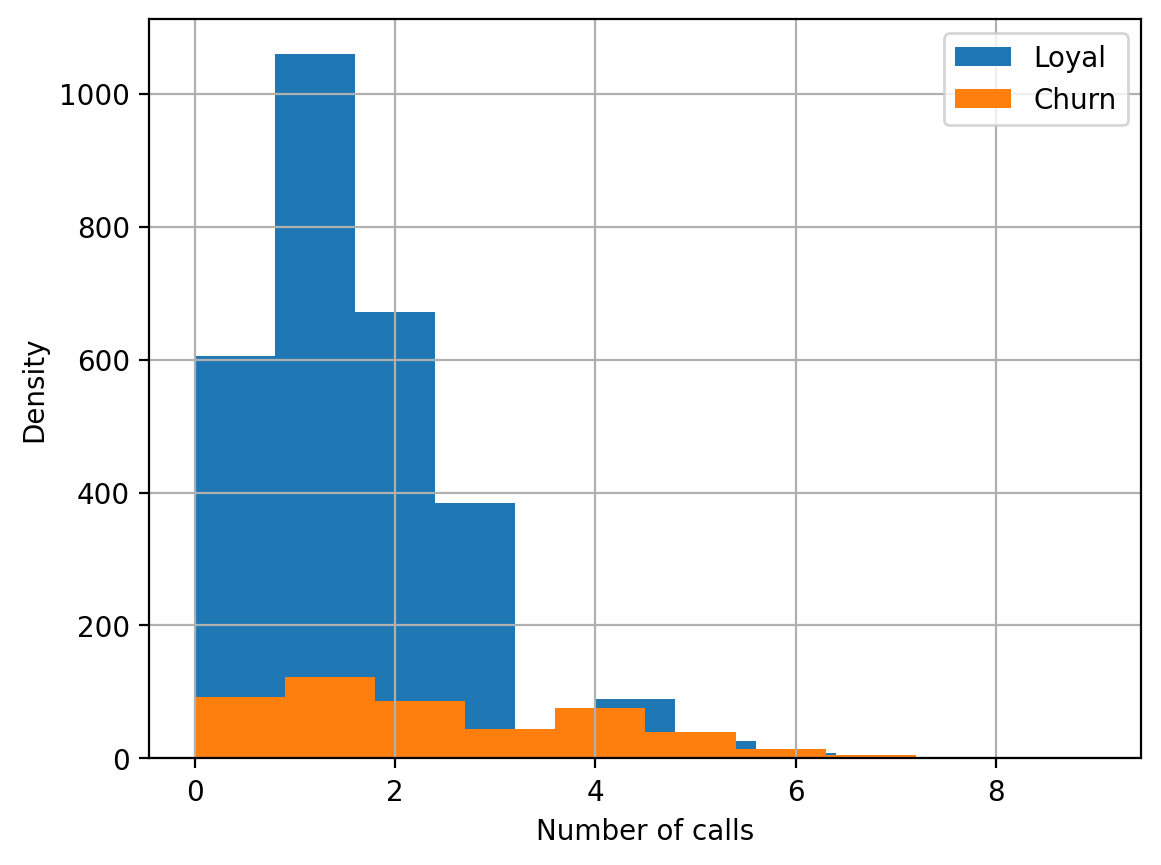
Looks like loyal customers make fewer calls to customer service than those who eventually leave. Now, it might be a good idea to estimate the average number of customer service calls in each group. Since our dataset is small, we would not get a good estimate by simply calculating the mean of the original sample. We will be better off applying the bootstrap method. Let’s generate 1000 new bootstrap samples from our original population and produce an interval estimate of the mean.
def get_bootstrap_samples(data, n_samples):
"""Generate bootstrap samples using the bootstrap method."""
indices = np.random.randint(0, len(data), (n_samples, len(data)))
samples = data[indices]
return samples
def stat_intervals(stat, alpha):
"""Produce an interval estimate."""
boundaries = np.percentile(stat, [100 * alpha / 2.0, 100 * (1 - alpha / 2.0)])
return boundaries
# Save the data about the loyal and former customers to split the dataset
loyal_calls = telecom_data.loc[
telecom_data["Churn"] == False, "Customer service calls"
].values
churn_calls = telecom_data.loc[
telecom_data["Churn"] == True, "Customer service calls"
].values
# Set the seed for reproducibility of the results
np.random.seed(0)
# Generate the samples using bootstrapping and calculate the mean for each of them
loyal_mean_scores = [
np.mean(sample) for sample in get_bootstrap_samples(loyal_calls, 1000)
]
churn_mean_scores = [
np.mean(sample) for sample in get_bootstrap_samples(churn_calls, 1000)
]
# Print the resulting interval estimates
print(
"Service calls from loyal: mean interval", stat_intervals(loyal_mean_scores, 0.05)
)
print(
"Service calls from churn: mean interval", stat_intervals(churn_mean_scores, 0.05)
)
Service calls from loyal: mean interval [1.4077193 1.49473684]
Service calls from churn: mean interval [2.0621118 2.39761905]
For the interpretation of confidence intervals, you can address this concise note or any course on statistics. It’s not correct to say that a confidence interval contains 95% of values. Note that the interval for the loyal customers is narrower, which is reasonable since they make fewer calls (0, 1 or 2) in comparison with the churned clients who call until they are fed up and decide to switch providers.
15.2.2. Bagging#
Now that you’ve grasped the idea of bootstrapping, we can move on to bagging.
Suppose that we have a training set \(\large X\). Using bootstrapping, we generate samples \(\large X_1, \dots, X_M\). Now, for each bootstrap sample, we train its own classifier \(\large a_i(x)\). The final classifier will average the outputs from all these individual classifiers. In the case of classification, this technique corresponds to voting: $\(\large a(x) = \frac{1}{M}\sum_{i = 1}^M a_i(x).\)$
The picture below illustrates this algorithm:
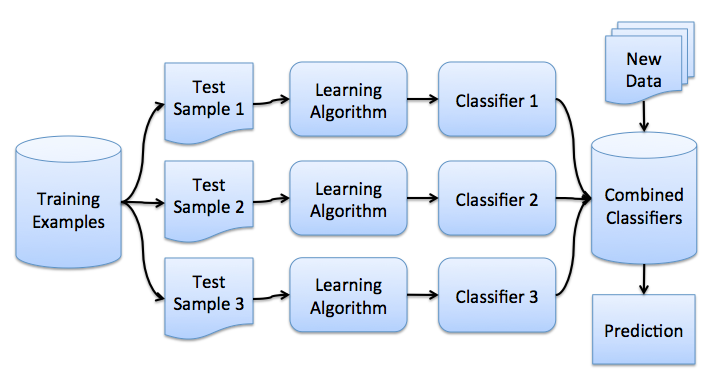
Fig. 15.3 Illustration of Bagging#
Let’s consider a regression problem with base algorithms \(\large b_1(x), \dots , b_n(x)\). Assume that there exists an ideal target function of true answers \(\large y(x)\) defined for all inputs and that the distribution \(\large p(x)\) is defined. We can then express the error for each regression function as follows:
And the expected value of the mean squared error:
Then, the mean error over all regression functions will look as follows:
We’ll assume that the errors are unbiased and uncorrelated, that is:
Now, let’s construct a new regression function that will average the values from the individual functions:
Let’s find its mean squared error:
Thus, by averaging the individual answers, we reduced the mean squared error by a factor of \(\large n\).
From our previous section, let’s recall the components that make up the total out-of-sample error:
Bagging reduces the variance of a classifier by decreasing the difference in error when we train the model on different datasets. In other words, bagging prevents overfitting. The efficiency of bagging comes from the fact that the individual models are quite different due to the different training data and their errors cancel each other out during voting. Additionally, outliers are likely omitted in some of the training bootstrap samples.
The scikit-learn library supports bagging with meta-estimators BaggingRegressor and BaggingClassifier. You can use most of the algorithms as a base.
Let’s examine how bagging works in practice and compare it with a decision tree. For this, we will use an example from sklearn’s documentation.
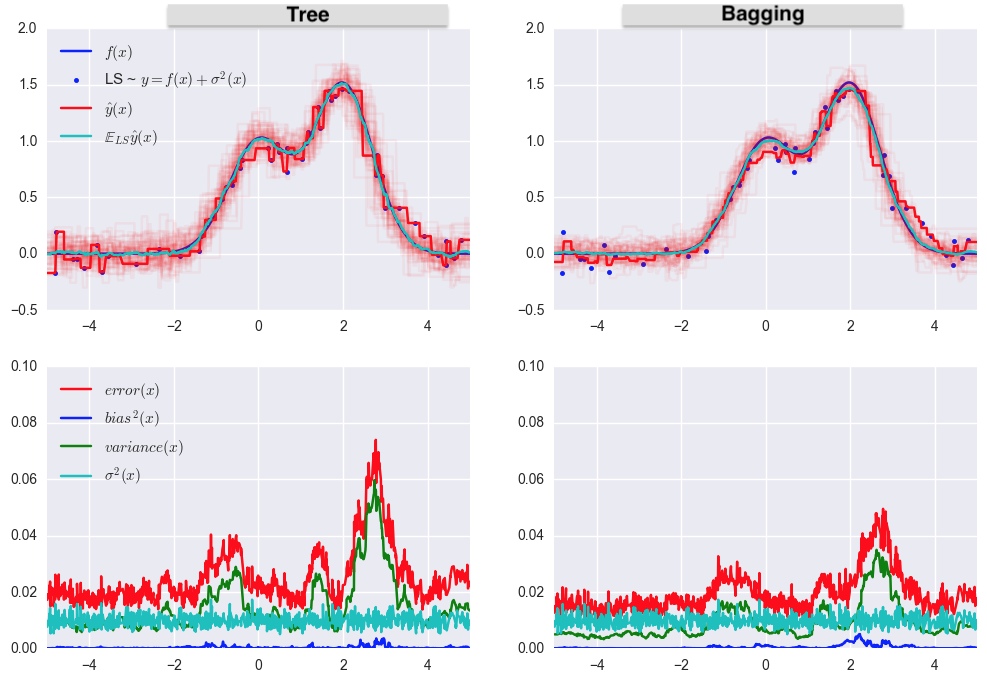
Fig. 15.4 Comparison of Bagging and Tree#
The error for the decision tree:
The error when using bagging:
As you can see from the graph above, the variance in the error is much lower for bagging. Remember that we have already proved this theoretically.
Bagging is effective on small datasets. Dropping even a small part of training data leads to constructing substantially different base classifiers. If you have a large dataset, you would generate bootstrap samples of a much smaller size.
The example above is unlikely to be applicable to any real work. This is because we made a strong assumption that our individual errors are uncorrelated. More often than not, this is way too optimistic for real-world applications. When this assumption is false, the reduction in error will not be as significant. In the following sections, we will discuss some more sophisticated ensemble methods, which enable more accurate predictions in real-world problems.
15.2.3. Out of bag error#
In case of Random Forest, there is no need to use cross-validation or hold-out samples in order to get an unbiased error estimation. Why? Because, in ensemble techniques, the error estimation takes place internally.
Random trees are constructed using different bootstrap samples of the original dataset. Approximately 37% of inputs are left out of a particular bootstrap sample and are not used in the construction of the \(\large k\)-th tree.
This is easy to prove. Suppose there are \(\large \ell\) examples in our dataset. At each step, each data point has equal probability of ending up in a bootstrap sample with replacement, probability \(\large\frac{1}{\ell}.\) The probability that there is no such bootstrap sample that contains a particular dataset element (i.e. it has been omitted \(\large \ell\) times) equals \(\large (1 - \frac{1}{\ell})^\ell\). When \(\large \ell \rightarrow +\infty\), it becomes equal to the Second Remarkable Limit \(\large \frac{1}{e}\). Then, the probability of selecting a specific example is \(\large \approx 1 - \frac{1}{e} \approx 63\%\).
Let’s visualize how Out-of-Bag Error (or OOBE) estimation works:
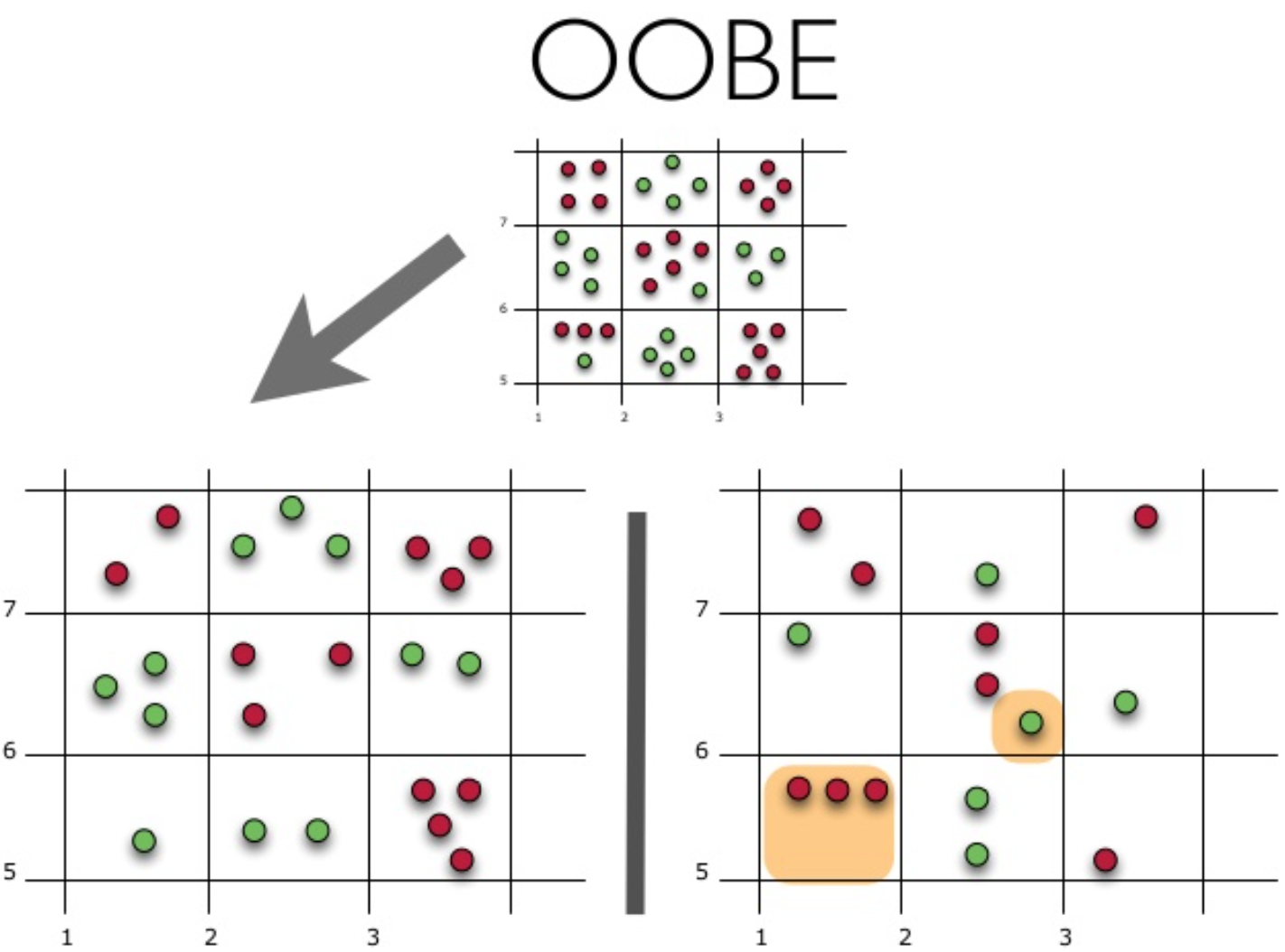
Fig. 15.5 Principle of OOBE#
The top part of the figure above represents our original dataset. We split it into the training (left) and test (right) sets. In the left image, we draw a grid that perfectly divides our dataset according to classes. Now, we use the same grid to estimate the share of the correct answers on our test set. We can see that our classifier gave incorrect answers in those 4 cases that have not been used during training (on the left). Hence, the accuracy of our classifier is \(\large \frac{11}{15}*100\% = 73.33\%\).
To sum up, each base algorithm is trained on \(\large \approx 63\%\) of the original examples. It can be validated on the remaining \(\large \approx 37\%\). The Out-of-Bag estimate is nothing more than the mean estimate of the base algorithms on those \(\large \approx 37\%\) of inputs that were left out of training.
15.2.4. Your turn! 🚀#
TBD
15.2.5. Acknowledgments#
Thanks to Yury Kashnitsky for creating the open-source content Ensembles and random forest. They inspire the majority of the content in this chapter.