Kernel method
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet numpy pandas matplotlib scikit-learn jupyterlab-myst ipython seaborn ipywidgets
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.svm import SVC
from sklearn.datasets import make_circles
from mpl_toolkits import mplot3d
from ipywidgets import interact, fixed
from sklearn.datasets import make_blobs
sns.set()
18. Kernel method#
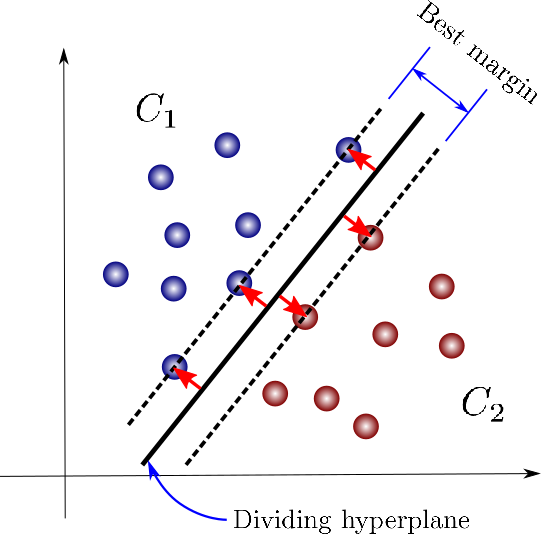
SVMs are a powerful and flexible class of algorithms used for classification and regression. In this section, we will explore the intuition behind SVMs and their use in classification problems. To start with, let’s understand the basic concept of SVMs. Support Vector Machines (SVMs) are supervised learning algorithms that can be used for classification and regression tasks. SVMs try to find the best decision boundary that separates data points of different classes. The decision boundary is chosen such that it maximizes the margin between the data points of different classes. The margin is defined as the minimum distance between the decision boundary and the closest data points of each class. This makes SVMs very robust to outliers as the decision boundary is chosen based on the data that is closest to it. In classification problems, the goal is to find a decision boundary that separates the data into two or more classes. SVMs can be used for binary classification, where the classes are only two, or for multiclass classification, where there are more than two classes.
from IPython.display import HTML
display(
HTML(
"""
<p style="text-align: center;">
<iframe src="https://static-1300131294.cos.ap-shanghai.myqcloud.com/html/svm-vis/demo1/demo.html" width="105%" height="700px;" style="border:none;"></iframe>
A demo of SVM. <a href="https://cs.stanford.edu/~karpathy/svmjs/demo/">[source]</a>
</p>
"""
)
)
A demo of SVM. [source]
from IPython.display import HTML
display(
HTML(
"""
<p style="text-align: center;">
<iframe src="https://static-1300131294.cos.ap-shanghai.myqcloud.com/html/svm-vis/demo2/index.html" width="105%" height="700px;" style="border:none;"></iframe>
A demo of SVM. <a href="http://macheads101.com/demos/svm-playground/">[source]</a>
</p>
"""
)
)
A demo of SVM. [source]
18.1. Motivating Support Vector Machines#
In this section we will consider differentiated classification: rather than modelling each category, we simply find a line or curve or flowform that separates these categories from each other.
# use seaborn plotting defaults
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.60)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
<matplotlib.collections.PathCollection at 0x7f3658ae3fa0>
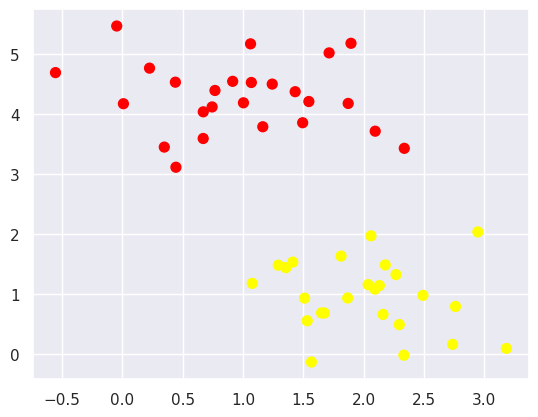
A linear discriminant classifier may draw straight lines to separate two sets of data, but there may be multiple split lines that perfectly distinguish between the two categories.
This is shown in the diagram below:
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plt.plot([0.6], [2.1], "x", color="red", markeredgewidth=2, markersize=10)
for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]:
plt.plot(xfit, m * xfit + b, "-k")
plt.xlim(-1, 3.5)
(-1.0, 3.5)
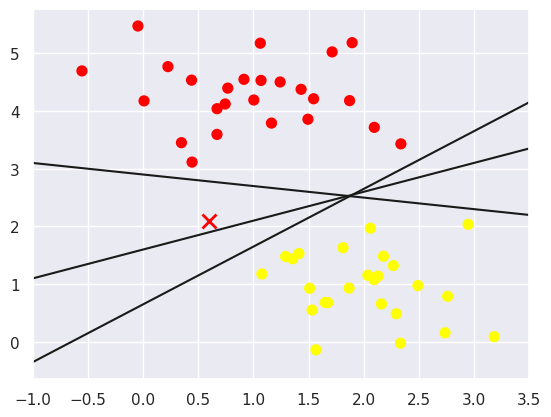
All three separators are good if we want to distinguish between these samples. But they have some significant differences. In the following, I will explain these separators with an example to show the difference between them. Now, suppose you want a new data point, which is marked with an “X” in this graph. So, which separator would you choose? This is a very interesting question! Because you can choose to give this new data point a different label. It’s up to you! Obviously we can’t simply “draw a line between classes”, but we do need to think a bit deeper.
18.2. Support Vector Machines: Maximizing the Margin#
SVM proposes a new solution algorithm which finds the nearest straight line by applying an appropriate boundary fill to each line. The following is an example of an improvement to the SVM algorithm.
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, "-k")
plt.fill_between(
xfit, yfit - d, yfit + d, edgecolor="none", color="#AAAAAA", alpha=0.4
)
plt.xlim(-1, 3.5)
(-1.0, 3.5)
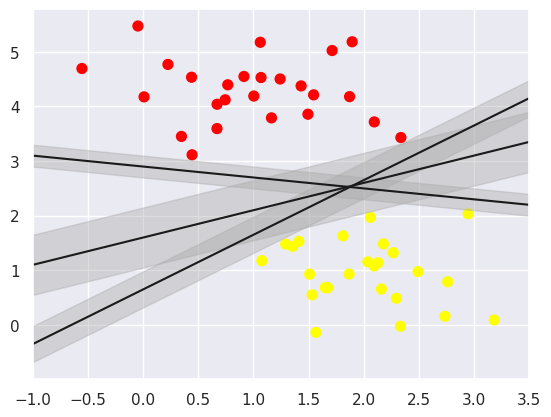
In SVM, the best models are those that maximise this margin, and SVM is an optimal model that achieves the maximum margin and can effectively use the boundary information in the dataset to predict the distribution of new data points, thereby improving prediction accuracy. Because of its excellent fitting ability, SVM can also be used to handle large amounts of unbalanced data.
18.3. Fitting a support vector machine#
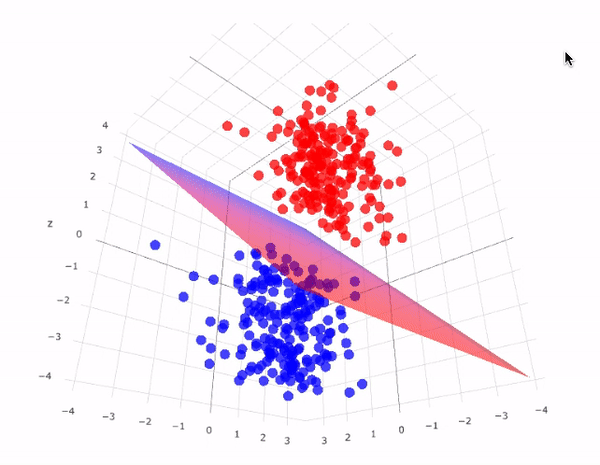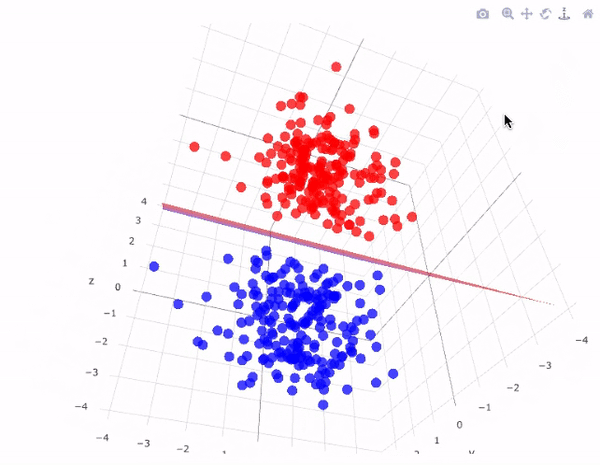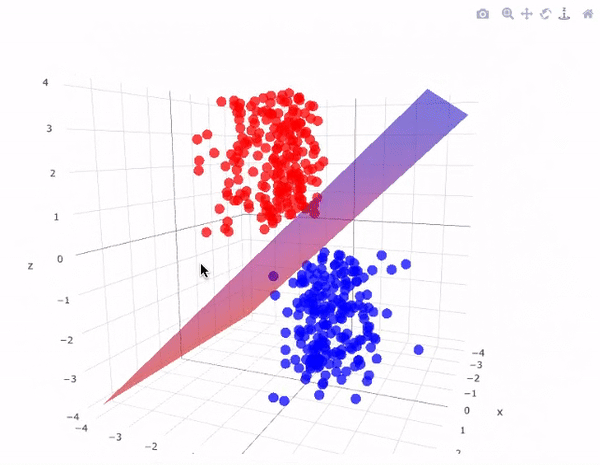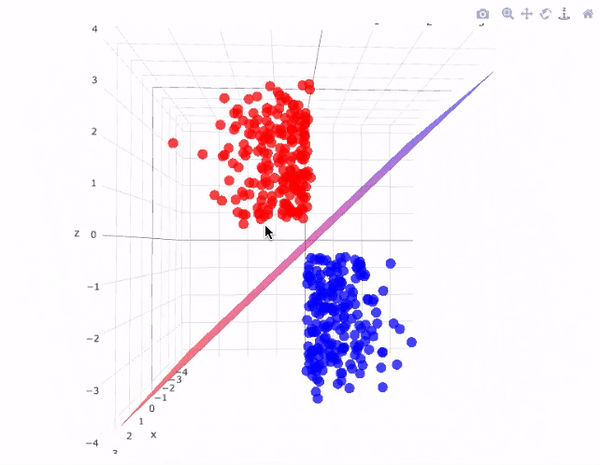
Now we will use a linear kernel and set the C parameter to a large size:
model = SVC(kernel="linear", C=1e10)
model.fit(X, y)
SVC(C=10000000000.0, kernel='linear')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC(C=10000000000.0, kernel='linear')
Let’s create a quick and easy function to draw the SVM decision boundary:
def plot_svc_decision_function(model, ax=None, plot_support=True):
"""Plot the decision function for a 2D SVC"""
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# create grid to evaluate model
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
# plot decision boundary and margins
ax.contour(
X, Y, P, colors="k", levels=[-1, 0, 1], alpha=0.5, linestyles=["--", "-", "--"]
)
# plot support vectors
if plot_support:
ax.scatter(
model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300,
linewidth=1,
facecolors="none",
)
ax.set_xlim(xlim)
ax.set_ylim(ylim)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plot_svc_decision_function(model)
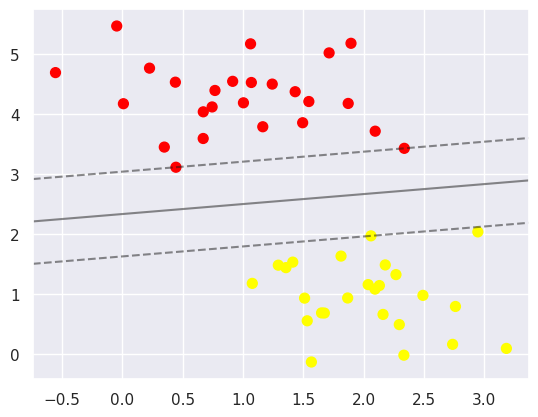
This is a maximum expansion of the space between the two points. Note that some of the practice points just reach the boundary and are marked with black circles. Those points are important in the matching process and are called, support vectors, which is the name of this algorithm. In Skeeter-learning, the identification of these points is stored in the support_vectors_ property of the classifier at:
model.support_vectors_
array([[0.44359863, 3.11530945],
[2.33812285, 3.43116792],
[2.06156753, 1.96918596]])
One of the main points of this classification method is that just the space in which the support vector is located has a large effect on the matching result; on the correct side, no point away from the boundary can correct the match. This is due to the fact that during the fitting process those points do not affect the loss function used in the model. Theoretically, this is due to the fact that during the fitting process, those points do not affect the loss function used in the fitting process, and therefore, if they do not cross the boundary, then their location and number are irrelevant.
In the dataset, the first 60 points and the first 120 points are each used as the training set, and we can use this dataset to train the model.
def plot_svm(N=10, ax=None):
X, y = make_blobs(n_samples=200, centers=2, random_state=0, cluster_std=0.60)
X = X[:N]
y = y[:N]
model = SVC(kernel="linear", C=1e10)
model.fit(X, y)
ax = ax or plt.gca()
ax.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
ax.set_xlim(-1, 4)
ax.set_ylim(-1, 6)
plot_svc_decision_function(model, ax)
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, N in zip(ax, [60, 120]):
plot_svm(N, axi)
axi.set_title("N = {0}".format(N))
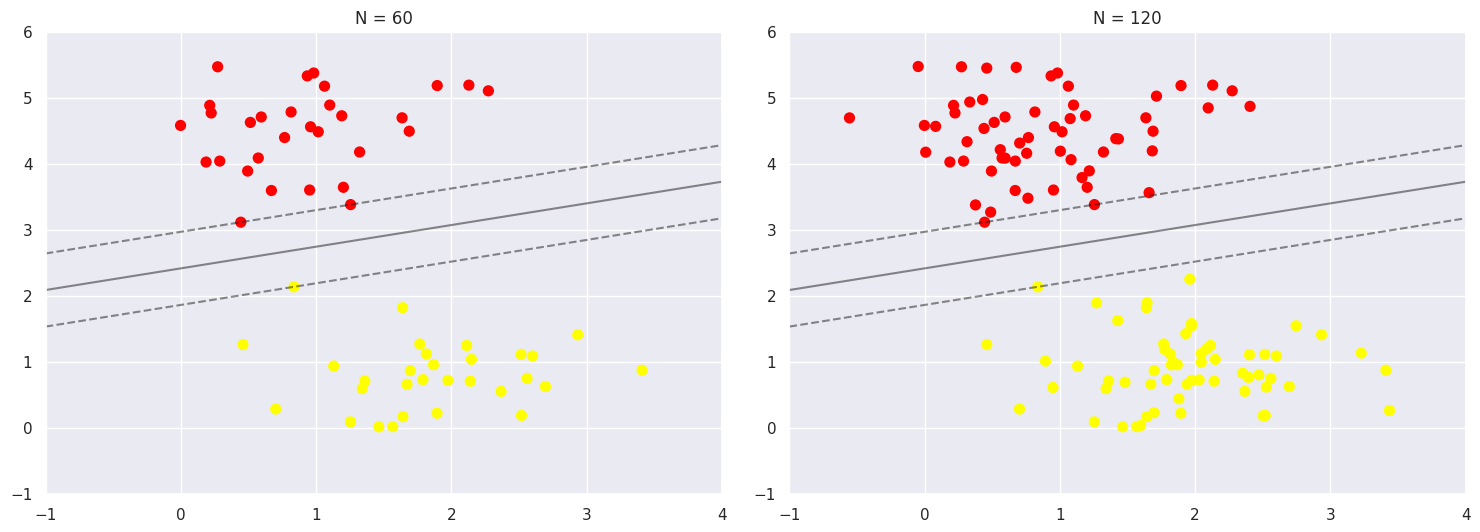
One of the strengths of the SVM model is that it is insensitive to the exact behaviour of distant points, as can be seen from the comparison between the two figures, and increases the number of training points without affecting the classification results of the model.
With the interactive component in IPython, you can interactively see this feature of the SVM model
interact(plot_svm, N=[10, 200], ax=fixed(None))
<function __main__.plot_svm(N=10, ax=None)>
18.4. Beyond linear boundaries: Kernel SVM#

Fig. 18.3 Kernel SVM visualization (with a polynomial kernel). source#
Kernels is an “easy algorithm” that saves us from the tedious calculations in a high-dimensional space. If support vector machines and kernels are combined to project data into a high-dimensional space, making it possible to handle non-linear relationships with linear classifiers, the power of SVMs can be enormous.
The following is the case for non-linearly separable data:
X, y = make_circles(100, factor=0.1, noise=0.1)
clf = SVC(kernel="linear").fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plot_svc_decision_function(clf, plot_support=False)
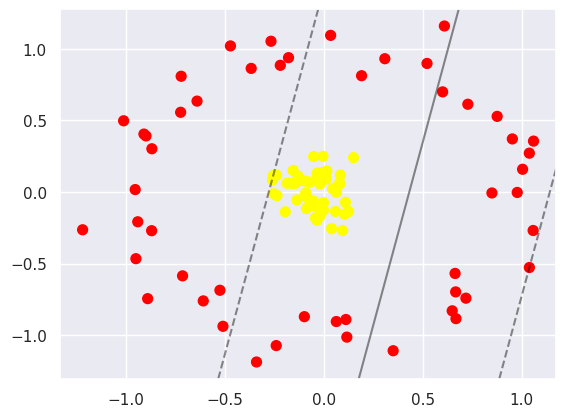
It is possible to project the data into higher dimensions, so that a linear partition line is sufficient. As an example, we can use a simple projection to compute a radial basis function with the centre on the middle block as follows:
r = np.exp(-(X**2).sum(1))
This additional dimension of data can be visualised in a 3D diagram.:
def plot_3D(elev=30, azim=30, X=X, y=y):
ax = plt.subplot(projection="3d")
ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap="autumn")
ax.view_init(elev=elev, azim=azim)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("r")
interact(plot_3D, elev=[-90, 90], azip=(-180, 180), X=fixed(X), y=fixed(y))
<function __main__.plot_3D(elev=30, azim=30, X=array([[ 0.72695865, 0.61217347],
[-0.06980878, -0.06535386],
[-0.72403294, 0.55606503],
[-0.89914723, 0.39106243],
[ 0.64802122, -0.83044319],
[-0.09220536, 0.07557321],
[-0.25328648, -0.01292604],
[-0.23701339, -0.02586378],
[ 0.11103053, -0.89105153],
[-0.03666822, -0.10134003],
[-0.0520438 , 0.24721249],
[-0.00517673, 0.24831493],
[-0.04289583, -0.18128915],
[-0.71431366, -0.58614995],
[-0.25920322, 0.0828926 ],
[-0.87051543, -0.27089099],
[ 0.1901678 , 0.81153461],
[ 0.12427444, -0.1369509 ],
[-0.94062022, -0.20860742],
[-0.95355479, 0.01630387],
[-0.36754765, 0.8626052 ],
[-0.02827206, 0.09335389],
[ 0.06298961, -0.00330911],
[-0.89062027, -0.745487 ],
[ 0.08101458, 0.05804313],
[ 0.10373246, -0.15652276],
[-0.16198782, 0.05988515],
[-0.1361291 , -0.05609278],
[ 1.00363487, 0.15809277],
[-0.09095918, -0.00846191],
[ 0.97651958, -0.0038309 ],
[-0.22046274, 0.88414574],
[ 0.0387728 , -0.25721551],
[-0.09373725, -0.01077873],
[ 0.87519405, 0.52747317],
[ 0.01193921, 0.09003989],
[-0.52551902, -0.68691744],
[ 1.05693449, -0.26940602],
[-0.11199879, 0.07929703],
[ 0.09415181, -0.2695779 ],
[-0.51013061, -0.93853 ],
[-0.90949902, 0.4038869 ],
[-0.00705796, 0.13627008],
[-1.01206358, 0.49663464],
[ 0.11560408, -1.01402248],
[-0.14492507, 0.06027793],
[-0.19527448, -0.13887305],
[-0.94992581, -0.46639509],
[-0.09896815, -0.87134419],
[-0.24108788, -1.07318342],
[-0.03479602, -0.19815024],
[-0.08858687, -0.11657987],
[-0.86937875, 0.30131287],
[ 0.07656532, 0.05697324],
[-0.4723203 , 1.01959477],
[-0.26749893, 1.05218035],
[ 0.01353271, 0.14419567],
[-0.05256775, -0.06370803],
[ 0.71726682, -0.74213767],
[-0.08508559, -0.03558351],
[-0.34062558, -1.1878968 ],
[ 0.60854808, 1.15861773],
[ 0.03383752, 1.09329258],
[-1.21925759, -0.26442375],
[-0.03427323, 0.13122417],
[ 0.66703806, -0.88508348],
[-0.25647447, 0.1133521 ],
[ 0.34963303, -1.10915221],
[ 0.66556 , -0.69828656],
[-0.15614068, 0.15066073],
[ 1.03796362, -0.52800664],
[ 0.52070164, 0.89707434],
[-0.03247996, 0.10322759],
[ 0.06251902, -0.90528237],
[ 1.03770163, 0.27057434],
[-0.60977435, -0.76121986],
[ 0.05844528, -0.13619598],
[-0.64115405, 0.63418542],
[ 1.05888933, 0.35477181],
[ 0.14963155, 0.23940268],
[ 0.10878975, -0.07242056],
[ 0.95190261, 0.37003449],
[ 0.84875799, -0.00737695],
[ 0.59971094, 0.69862986],
[ 0.30763498, 0.93010633],
[-0.00194801, -0.07494378],
[-0.23916152, 0.11728109],
[ 0.04345987, 0.02201485],
[-0.17897757, 0.93746402],
[-0.02119326, -0.16934947],
[ 0.08308495, 0.11829303],
[-0.13052308, 0.11098761],
[-0.02083421, 0.05496652],
[-0.00198481, -0.12697529],
[ 0.01426998, 0.14678327],
[-0.18617708, 0.06005862],
[-0.07178292, 0.06797343],
[ 0.6625369 , -0.56936445],
[-0.72140221, 0.80764928],
[-0.04390094, -0.10202519]]), y=array([0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1,
1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0,
0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0,
1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1,
0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1]))>
Next we describe how to select and adjust the radial basis function centres. This type of basis function transformation is known as a kernel transformation, and this form of transformation solves the problem of shifting the centre of the basis function to a certain extent. However there is a disadvantage: there is the problem of computational overload as a new basis function needs to be computed each time. We can solve this problem with the help of the “kernel trick” applet, where we change the original linear kernel to a radial basis function kernel and then use the kernel model hyperparameters.
clf = SVC(kernel="rbf", C=1e6)
clf.fit(X, y)
SVC(C=1000000.0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC(C=1000000.0)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plot_svc_decision_function(clf)
plt.scatter(
clf.support_vectors_[:, 0],
clf.support_vectors_[:, 1],
s=300,
lw=1,
facecolors="none",
)
<matplotlib.collections.PathCollection at 0x7f36565ebb80>
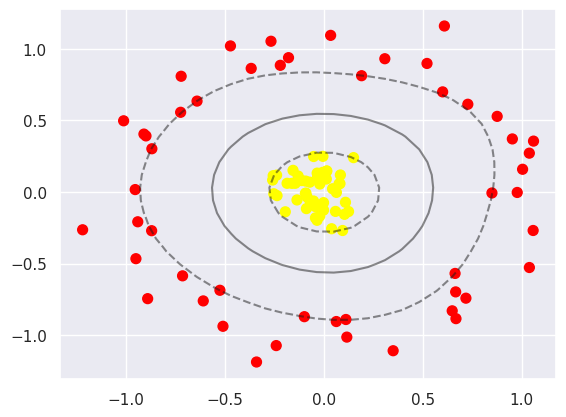
Currently, for linearly divisible data, we usually use a linear support vector machine. However, if the data is non-linear, such as a classification problem, we can transform it into a linearly divisible problem, thus improving the generalisation of the model. In this case, kernel tricks are used to transform linearly divisible problems into non-linearly divisible problems.
18.5. Hinge loss#
An alternative to cross-entropy for binary classification problems is the hinge loss function. It is mainly studied for the Support Vector Machine (SVM) model. It is designed to perform binary classification of target values which in the set {-1, 1}
18.6. RBF Kernel#
from IPython.display import HTML
display(
HTML(
"""
<p style="text-align: center;">
<iframe src="https://www.youtube.com/embed/NYwVM6_EuxQ" width="105%" height="700px;" style="border:none;"></iframe>
video of RBF kernel. <a href="https://www.youtube.com/embed/NYwVM6_EuxQ">[source]</a>
</p>
"""
)
)
video of RBF kernel. [source]
18.7. Support Vector Regression (SVR)#
SVR regression (Squeeze-and-VectorRegression), also known as Squeeze Regression, is an optimisation problem. The basic idea is to find a regression plane such that the variables in all data sets are closest to a point on this plane, so that all points on the plane are correlated. Objective function: In SVR regression, the objective function is to minimise the two-parametric number of weights while keeping the points in each training set as far away as possible from the support vector on one side of their own category.
18.8. {figure} https://static-1300131294.cos.ap-shanghai.myqcloud.com/images/svm/svr1.jpeg#
{kind=link}
18.9. name: support vector regression width: 90%#
An illustration of support vector regression
18.10. SVM v.s. logistic regression#
Similarities: Both are linear classification algorithms Differences:
Different loss functions LR: based on the assumption of “given x and parameters, y obeys binomial distribution”, derived from the maximum likelihood estimation SVM: standard representation of hinge loss + L2 regularization, based on the principle of geometric interval maximization
Support vector machines only consider local points near the interval boundary, whereas logistic regression considers the global (points far from the boundary line also play a role in determining the boundary line). Support vector machines do not cause changes in the separation hyperplane by changing the non-support vector samples
SVM’s loss function is self-regularising, which is why SVM is a structural risk minimisation algorithm!!! And LR must additionally add a regular term to the loss function !!! Structural risk minimisation, meaning seeking a balance between training error and model complexity to prevent overfitting.
Optimization methods: LR is generally based on gradient descent, SVM on SMO
For non-linear separable problems, SVM is more scalable than LR
https://www.geeksforgeeks.org/differentiate-between-support-vector-machine-and-logistic-regression/
18.11. SVR v.s. linear regression#
The problem of overfitting is a very tricky one in the field of statistics. In this case, many machine learning methods, such as least squares (OLSE), will perform poorly. Support vector machines (SVR), on the other hand, can minimise the overfitting problem. SVR allows for non-linear fitting when there is enough data for training. A final issue to consider is OLSE linear regression. While linear regression is effective for most problems, it is not always effective for some special cases. For example, in OLSE linear regression, there is some bias in fitting the variables linearly because the model is not hyperplane. In contrast, SVR allows for non-linear fitting problems.
18.12. Support Vector Machine Summary#
The basic model of SVM: is defined as a linear classifier with maximum interval on the feature space. Specifically, when linearly separable, it finds the optimal classification hyperplane for both classes of samples in the original space. When linearly indistinguishable, relaxation variables are added and samples from a low-dimensional input space are mapped to a higher-dimensional space via a non-linear mapping to make them linearly distinguishable, so that the optimal classification hyperplane can be found in that feature space.
Advantages of SVM:
Solves machine learning in the small sample case.
No increase in computational complexity when mapping to higher dimensional spaces as the dimensional catastrophe and non-linear differentiability are overcome by using the kernel function approach. (Since the final decision function of the support vector machine algorithm is determined by only a small number of support vectors, the computational complexity depends on the number of support vectors rather than the dimensionality of the entire sample space). Disadvantages of SVMs:
Support vector machine algorithms are difficult to implement for large training samples. This is because support vector algorithms solve support vectors with the help of quadratic programming, which will be designed to compute matrices of order m, so a large amount of machine memory and computing time will be consumed when the order of the matrix is large.
The classical SVM only gives algorithms for binary classification, while in data mining, it is generally necessary to solve multi-classification classification problems, and support vector machines are not ideal for solving multi-classification problems.
The common SVM theories nowadays use a fixed penalty factor C, but the losses caused by two kinds of errors in positive and negative samples are different.
18.13. [Optional] Let’s dive into the math of SVM …#
from IPython.display import HTML
display(
HTML(
"""
<p style="text-align: center;">
<iframe src="https://www.youtube.com/embed/05VABNfa1ds" width="105%" height="700px;" style="border:none;"></iframe>
math of SVM. <a href="https://www.youtube.com/embed/05VABNfa1ds">[source]</a>
</p>
"""
)
)
math of SVM. [source]
18.14. Your turn! 🚀#
You can follow this assignment to practise Support Vector Machines with examples.
18.15. Acknowledgement#
Thanks for jakevdp, for which the code part is licenced under MIT licence.