Fun with Variational Autoencoders
Contents
42.108. Fun with Variational Autoencoders#
This is a starter kernel to use Labelled Faces in the Wild (LFW) Dataset in order to maintain knowledge about main Autoencoder principles. PyTorch will be used for modelling.
42.108.1. Fork it and give it an upvote.#
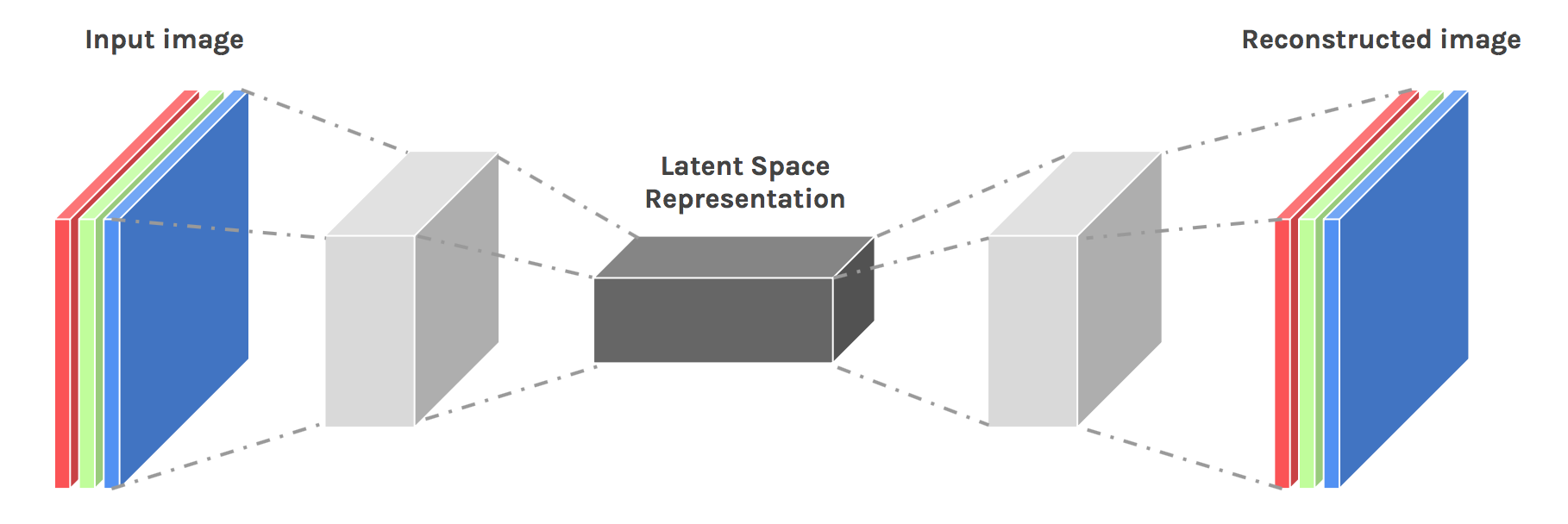
Useful links:
42.108.2. A bit of theory#
“Autoencoding” is a data compression algorithm where the compression and decompression functions are 1) data-specific, 2) lossy, and 3) learned automatically from examples rather than engineered by a human. Additionally, in almost all contexts where the term “autoencoder” is used, the compression and decompression functions are implemented with neural networks.
Autoencoders are data-specific, which means that they will only be able to compress data similar to what they have been trained on. This is different from, say, the MPEG-2 Audio Layer III (MP3) compression algorithm, which only holds assumptions about “sound” in general, but not about specific types of sounds. An autoencoder trained on pictures of faces would do a rather poor job of compressing pictures of trees, because the features it would learn would be face-specific.
Autoencoders are lossy, which means that the decompressed outputs will be degraded compared to the original inputs (similar to MP3 or JPEG compression). This differs from lossless arithmetic compression.
Autoencoders are learned automatically from data examples, which is a useful property: it means that it is easy to train specialized instances of the algorithm that will perform well on a specific type of input. It doesn’t require any new engineering, just appropriate training data.
source: https://blog.keras.io/building-autoencoders-in-keras.html
import matplotlib.pyplot as plt
import os
import glob
import pandas as pd
import random
import numpy as np
# import cv2
import base64
import imageio
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data_utils
import requests
import zipfile
from copy import deepcopy
from torch.autograd import Variable
from tqdm import tqdm
from pprint import pprint
from PIL import Image
from sklearn.model_selection import train_test_split
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('Training on',DEVICE)
42.108.3. Load datasets#
datasets_url = "https://static-1300131294.cos.ap-shanghai.myqcloud.com/data/deep-learning/autoencoder/variational-autoencoder-and-faces-generation/lfw-deepfunneled.zip"
attributes_url = "https://static-1300131294.cos.ap-shanghai.myqcloud.com/data/deep-learning/autoencoder/variational-autoencoder-and-faces-generation/lfw_attributes.txt"
model_url = "https://static-1300131294.cos.ap-shanghai.myqcloud.com/data/deep-learning/autoencoder/variational-autoencoder-and-faces-generation/variational-autoencoder-and-faces-generation.pth"
model_vae_url = "https://static-1300131294.cos.ap-shanghai.myqcloud.com/data/deep-learning/autoencoder/variational-autoencoder-and-faces-generation/vae_model.pth"
notebook_path = os.getcwd()
tmp_folder_path = os.path.join(notebook_path, "tmp")
if not os.path.exists(tmp_folder_path):
os.makedirs(tmp_folder_path)
file_path = os.path.join(tmp_folder_path,"autoencoder")
if not os.path.exists(file_path):
os.makedirs(file_path)
zip_store_path = os.path.join(file_path, "zip-store")
if not os.path.exists(zip_store_path):
os.makedirs(zip_store_path)
datasets_response = requests.get(datasets_url)
attributes_response = requests.get(attributes_url)
model_response = requests.get(model_url)
model_vae_response = requests.get(model_url)
datasets_name = os.path.basename(datasets_url)
attributes_name = os.path.basename(attributes_url)
model_name = os.path.basename(model_url)
model_vae_name = os.path.basename(model_url)
datasets_save_path = os.path.join(zip_store_path, datasets_name)
attributes_save_path = os.path.join(file_path, attributes_name)
model_save_path = os.path.join(file_path, model_name)
model_vae_save_path = os.path.join(file_path, model_name)
with open(datasets_save_path, "wb") as file:
file.write(datasets_response.content)
with open(attributes_save_path, "wb") as file:
file.write(attributes_response.content)
with open(model_save_path, "wb") as file:
file.write(model_response.content)
with open(model_vae_save_path, "wb") as file:
file.write(model_vae_response.content)
zip_file_path = f"./tmp/variational-autoencoder-and-faces-generation/zip-store/{datasets_name}"
extract_path = "./tmp/variational-autoencoder-and-faces-generation"
zip_ref = zipfile.ZipFile(zip_file_path, 'r')
zip_ref.extractall(extract_path)
zip_ref.close()
DATASET_PATH ="./tmp/variational-autoencoder-and-faces-generation/lfw-deepfunneled/"
ATTRIBUTES_PATH = "./tmp/variational-autoencoder-and-faces-generation/lfw_attributes.txt"
42.108.4. Explore the data#
Image data is collected from DATASET_PATH and a dataset is created in which the person information for each image is extracted and used for subsequent data analysis or processing. Finally, the filter() function is used to limit the size of the dataset by retaining only information about people who appear less than 25 times.
dataset = []
for path in glob.iglob(os.path.join(DATASET_PATH, "**", "*.jpg")):
person = path.split("/")[-2]
dataset.append({"person":person, "path": path})
dataset = pd.DataFrame(dataset)
dataset = dataset.groupby("person").filter(lambda x: len(x) < 25 )
dataset.head(10)
Let’s group the dataset and look at the amount of photo data for the first 200 people.
dataset.groupby("person").count()[:200].plot(kind='bar', figsize=(20,5))
And take a random look at the photos of people in the dataset.
plt.figure(figsize=(20,10))
for i in range(20):
idx = random.randint(0, len(dataset))
img = plt.imread(dataset.path.iloc[idx])
plt.subplot(4, 5, i+1)
plt.imshow(img)
plt.title(dataset.person.iloc[idx])
plt.xticks([])
plt.yticks([])
plt.tight_layout()
plt.show()
42.108.5. Prepare the dataset#
Reads the attribute data from the txt file at the specified path and stores it in a DataFrame object called df_attrs. The txt file is tab delimited, skipping the first line.
Empty list photo_ids for storing photo IDs, paths and person information. Use os.walk() to iterate through the files and folders under the specified path. For each file, if the filename ends in .jpg, extract its path, person information and photo number and add them to the photo_ids list.
Then convert the photo_ids list into a DataFrame object and merge it with df_attrs, based on common columns (“person” and “imagenum”). The result is stored in a DataFrame object called df.
Use the assertion statement to check that the length of the merged DataFrame object is the same as the length of the original attribute data to ensure that no data is missing.
Based on the paths of the photos in the merged DataFrame, the image data for each photo is read using the imageio.imread() function. Each image is then subjected to a series of processes, including cropping, resizing, etc., and the processed image data is stored in a NumPy array called all_photos.
Remove the photo path, person information and photo number from the merged DataFrame and store the result in a DataFrame object called all_attrs.
def fetch_dataset(dx=80,dy=80, dimx=45,dimy=45):
df_attrs = pd.read_csv(ATTRIBUTES_PATH, sep='\t', skiprows=1,)
df_attrs = pd.DataFrame(df_attrs.iloc[:,:-1].values, columns = df_attrs.columns[1:])
photo_ids = []
for dirpath, dirnames, filenames in os.walk(DATASET_PATH):
for fname in filenames:
if fname.endswith(".jpg"):
fpath = os.path.join(dirpath,fname)
photo_id = fname[:-4].replace('_',' ').split()
person_id = ' '.join(photo_id[:-1])
photo_number = int(photo_id[-1])
photo_ids.append({'person':person_id,'imagenum':photo_number,'photo_path':fpath})
photo_ids = pd.DataFrame(photo_ids)
df = pd.merge(df_attrs,photo_ids,on=('person','imagenum'))
assert len(df)==len(df_attrs),"lost some data when merging dataframes"
all_photos = df['photo_path'].apply(imageio.imread)\
.apply(lambda img:img[dy:-dy,dx:-dx])\
.apply(lambda img: np.array(Image.fromarray(img).resize([dimx,dimy])) )
all_photos = np.stack(all_photos.values).astype('uint8')
all_attrs = df.drop(["photo_path","person","imagenum"],axis=1)
return all_photos,all_attrs
data, attrs = fetch_dataset()
Get the height and width of the image from data and define the number of channels.
#45,45
IMAGE_H = data.shape[1]
IMAGE_W = data.shape[2]
N_CHANNELS = 3
Normalize the data and divide the training and test sets.
data = np.array(data / 255, dtype='float32')
X_train, X_val = train_test_split(data, test_size=0.2, random_state=42)
X_train = torch.FloatTensor(X_train)
X_val = torch.FloatTensor(X_val)
42.108.6. Building simple autoencoder#
dim_z=100
X_train.shape
class Autoencoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(45*45*3,1500),
nn.BatchNorm1d(1500),
nn.ReLU(),
nn.Linear(1500,1000),
nn.BatchNorm1d(1000),
nn.ReLU(),
nn.Linear(1000, dim_z),
nn.BatchNorm1d(dim_z),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(dim_z,1000),
nn.BatchNorm1d(1000),
nn.ReLU(),
#nn.Linear(500,1000),
#nn.ReLU(),
nn.Linear(1000,1500),
nn.BatchNorm1d(1500),
nn.ReLU(),
nn.Linear(1500,45*45*3)
)
def encode(self,x):
return self.encoder(x)
def decode(self,z):
return self.decoder(z)
def forward(self, x):
encoded = self.encode(x)
decoded = self.decode(encoded)
return encoded, decoded
This model will not be used in the following codes, but you can use it to instead of Autoencoder() to see the difference.
class Autoencoder_cnn(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=16, out_channels=8, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(in_channels=8, out_channels=16, kernel_size=5, stride=2),
nn.ReLU(),
nn.ConvTranspose2d(in_channels=16, out_channels=3, kernel_size=5, stride=2),
#nn.ReLU(),
#nn.ConvTranspose2d(in_channels=8, out_channels=8, kernel_size=3, stride=2),
#nn.ReLU(),
#nn.ConvTranspose2d(in_channels=8, out_channels=3, kernel_size=5, stride=2)
)
def decode(self,z):
return self.decoder(z)
def forward(self, x):
x = x.permute(0,3,1,2)
encoded = self.encoder(x)
decoded = self.decode(encoded)
return encoded, decoded
model_auto = Autoencoder().to(DEVICE)
42.108.7. Train autoencoder#
get_batch: It uses the Generator method to generate batches of a specified size by iterating over them. The amount of data generated is batch_size each time, until the entire data set is traversed.
plot_gallery: This function is used to visualise an image.
fit_epoch: This function is used to perform the training process of the model. The function traverses the training data set, feeds the data into the model for forward propagation, calculates losses, back propagation and parameter updates. Finally the training loss is returned.
eval_epoch: This function is used to perform the validation process of the model. The function traverses the validation data set, feeds the data into the model for forward propagation and calculates the loss. Finally the validation loss is returned.
def get_batch(data, batch_size=64):
total_len = data.shape[0]
for i in range(0, total_len, batch_size):
yield data[i:min(i+batch_size,total_len)]
def plot_gallery(images, h, w, n_row=3, n_col=6, with_title=False, titles=[]):
plt.figure(figsize=(1.5 * n_col, 1.7 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
try:
plt.imshow(images[i].reshape((h, w, 3)), cmap=plt.cm.gray, vmin=-1, vmax=1, interpolation='nearest')
if with_title:
plt.title(titles[i])
plt.xticks(())
plt.yticks(())
except:
pass
def fit_epoch(model, train_x, criterion, optimizer, batch_size, is_cnn=False):
running_loss = 0.0
processed_data = 0
for inputs in get_batch(train_x,batch_size):
if not is_cnn:
inputs = inputs.view(-1, 45*45*3)
inputs = inputs.to(DEVICE)
optimizer.zero_grad()
encoder, decoder = model(inputs)
#print('decoder shape: ', decoder.shape)
if not is_cnn:
outputs = decoder.view(-1, 45*45*3)
else:
outputs = decoder.permute(0,2,3,1)
loss = criterion(outputs,inputs)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.shape[0]
processed_data += inputs.shape[0]
train_loss = running_loss / processed_data
return train_loss
def eval_epoch(model, x_val, criterion, is_cnn=False):
running_loss = 0.0
processed_data = 0
model.eval()
for inputs in get_batch(x_val):
if not is_cnn:
inputs = inputs.view(-1, 45*45*3)
inputs = inputs.to(DEVICE)
with torch.set_grad_enabled(False):
encoder, decoder = model(inputs)
if not is_cnn:
outputs = decoder.view(-1, 45*45*3)
else:
outputs = decoder.permute(0,2,3,1)
loss = criterion(outputs,inputs)
running_loss += loss.item() * inputs.shape[0]
processed_data += inputs.shape[0]
val_loss = running_loss / processed_data
#draw
with torch.set_grad_enabled(False):
pic = x_val[3]
if not is_cnn:
pic_input = pic.view(-1, 45*45*3)
else:
pic_input = torch.FloatTensor(pic.unsqueeze(0))
pic_input = pic_input.to(DEVICE)
encoder, decoder = model(pic_input)
if not is_cnn:
pic_output = decoder.view(-1, 45*45*3).squeeze()
else:
pic_output = decoder.permute(0,2,3,1)
pic_output = pic_output.to("cpu")
pic_input = pic_input.to("cpu")
plot_gallery([pic_input, pic_output],45,45,1,2)
return val_loss
def train(train_x, val_x, model, epochs=10, batch_size=32, is_cnn=False):
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
history = []
log_template = "\nEpoch {ep:03d} train_loss: {t_loss:0.4f} val_loss: {val_loss:0.4f}"
with tqdm(desc="epoch", total=epochs) as pbar_outer:
for epoch in range(epochs):
train_loss = fit_epoch(model,train_x,criterion,optimizer,batch_size,is_cnn)
val_loss = eval_epoch(model,val_x,criterion, is_cnn)
print("loss: ", train_loss)
history.append((train_loss,val_loss))
pbar_outer.update(1)
tqdm.write(log_template.format(ep=epoch+1, t_loss=train_loss, val_loss=val_loss))
return history
# history = train(X_train, X_val, model_auto, epochs=50, batch_size=64)
# torch.save(history,"variational-autoencoder-and-faces-generation.pth")
history = torch.load("./tmp/variational-autoencoder-and-faces-generation/variational-autoencoder-and-faces-generation.pth")
train_loss, val_loss = zip(*history)
plt.figure(figsize=(15,10))
plt.plot(train_loss, label='Train loss')
plt.plot(val_loss, label='Val loss')
plt.legend(loc='best')
plt.xlabel("epochs")
plt.ylabel("loss")
plt.plot();
42.108.8. Sampling#
Let’s generate some samples from random vectors
z = np.random.randn(25, dim_z)
print(z.shape)
with torch.no_grad():
inputs = torch.FloatTensor(z)
inputs = inputs.to(DEVICE)
model_auto.eval()
output = model_auto.decode(inputs)
plot_gallery(output.data.cpu().numpy(), IMAGE_H, IMAGE_W, n_row=5, n_col=5)
42.108.9. Adding smile and glasses#
Let’s find some attributes like smiles or glasses on the photo and try to add it to the photos which don’t have it. We will use the second dataset for it. It contains a bunch of such attributes.
attrs.head()
attrs.columns
smile_ids = attrs['Smiling'].sort_values(ascending=False).iloc[100:125].index.values
smile_data = data[smile_ids]
no_smile_ids = attrs['Smiling'].sort_values(ascending=True).head(25).index.values
no_smile_data = data[no_smile_ids]
eyeglasses_ids = attrs['Eyeglasses'].sort_values(ascending=False).head(25).index.values
eyeglasses_data = data[eyeglasses_ids]
sunglasses_ids = attrs['Sunglasses'].sort_values(ascending=False).head(25).index.values
sunglasses_data = data[sunglasses_ids]
plot_gallery(smile_data, IMAGE_H, IMAGE_W, n_row=5, n_col=5, with_title=True, titles=smile_ids)
plot_gallery(no_smile_data, IMAGE_H, IMAGE_W, n_row=5, n_col=5, with_title=True, titles=no_smile_ids)
plot_gallery(eyeglasses_data, IMAGE_H, IMAGE_W, n_row=5, n_col=5, with_title=True, titles=eyeglasses_ids)
plot_gallery(sunglasses_data, IMAGE_H, IMAGE_W, n_row=5, n_col=5, with_title=True, titles=sunglasses_ids)
Calculating latent space vector for the selected images.
def to_latent(pic):
with torch.no_grad():
inputs = torch.FloatTensor(pic.reshape(-1, 45*45*3))
inputs = inputs.to(DEVICE)
model_auto.eval()
output = model_auto.encode(inputs)
return output
def from_latent(vec):
with torch.no_grad():
inputs = vec.to(DEVICE)
model_auto.eval()
output = model_auto.decode(inputs)
return output
smile_latent = to_latent(smile_data).mean(axis=0)
no_smile_latent = to_latent(no_smile_data).mean(axis=0)
sunglasses_latent = to_latent(sunglasses_data).mean(axis=0)
smile_vec = smile_latent-no_smile_latent
sunglasses_vec = sunglasses_latent - smile_latent
def make_me_smile(ids):
for id in ids:
pic = data[id:id+1]
latent_vec = to_latent(pic)
latent_vec[0] += smile_vec
pic_output = from_latent(latent_vec)
pic_output = pic_output.view(-1,45,45,3).cpu()
plot_gallery([pic,pic_output], IMAGE_H, IMAGE_W, n_row=1, n_col=2)
def give_me_sunglasses(ids):
for id in ids:
pic = data[id:id+1]
latent_vec = to_latent(pic)
latent_vec[0] += sunglasses_vec
pic_output = from_latent(latent_vec)
pic_output = pic_output.view(-1,45,45,3).cpu()
plot_gallery([pic,pic_output], IMAGE_H, IMAGE_W, n_row=1, n_col=2)
make_me_smile(no_smile_ids)
give_me_sunglasses(smile_ids)
While the concept is pretty straightforward the simple autoencoder have some disadvantages. Let’s explore them and try to do better.
42.108.10. Variational autoencoder#
So far we have trained our encoder to reconstruct the very same image that we’ve transfered to latent space. That means that when we’re trying to generate new image from the point decoder never met we’re getting the best image it can produce, but the quelity is not good enough.
In other words the encoded vectors may not be continuous in the latent space.
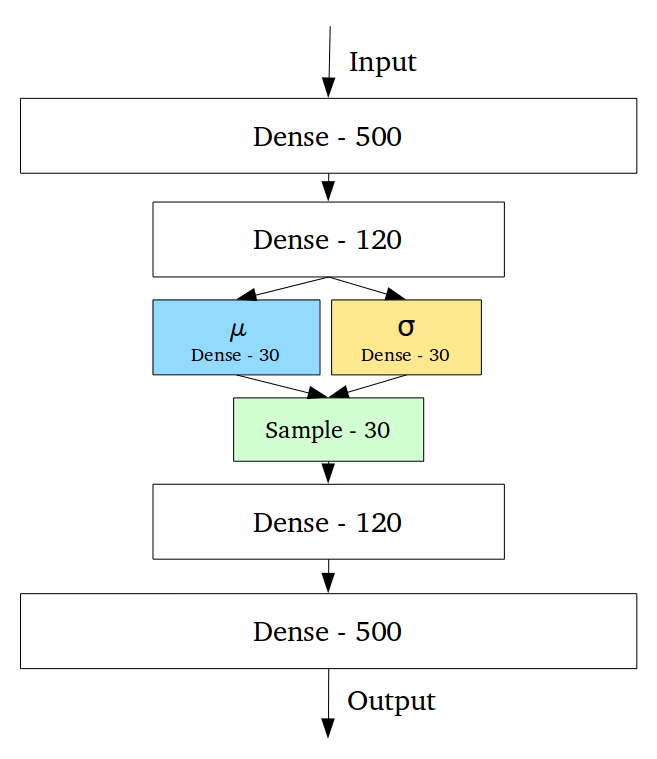
In other hand Variational Autoencoders makes not only one encoded vector but two:
vector of means, μ;
vector of standard deviations, σ.
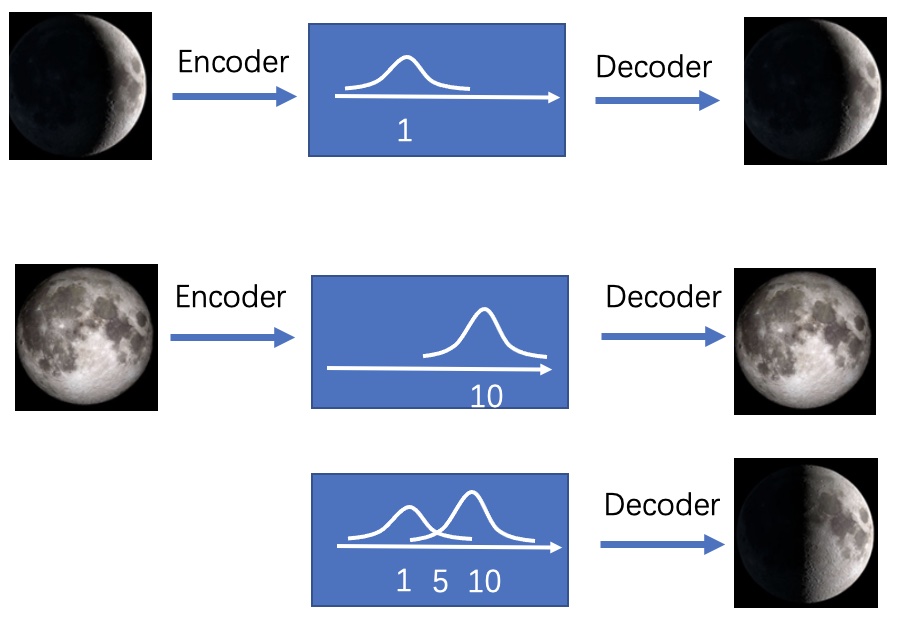
So we’re going to try to use VAE to create better new data. The difference in thinking between VAE and AE is that VAE does not map images as “numerical codes”, but as “distributions”.
It will be easier to understand with another simpler example, if we map the ‘new moon’ image to a normal distribution with µ=1, then it is equivalent to adding noise around 1, where not only does 1 represent the ‘new moon’, but the values around 1 also represent The “new moon” is not only represented by 1, but also by the values around 1, except that 1 is most like the “new moon”. Mapping the “full moon” to a normal distribution with µ=10, all values around 10 also represent the “full moon”. Then with code=5, it has the characteristics of both a ‘new moon’ and a ‘full moon’, so the probability of decoding is a ‘half moon’. This is the idea behind VAE.
The overall structure of VAE is similar to that of AE, except that the Encoder of AE outputs the code directly, whereas the Encoder of VAE outputs a number of normally distributed means (μ1, μ2…μn) and standard deviations (σ1,σ2…σn), and then from each normal distribution N(μ1,σ21),N(μ2,σ22)…N(μn,σ2n) Sampling gives the code (Z1,Z2…Zn) and the code is fed to the Decoder for decoding.
dim_z = 256
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(45*45*3, 1500)
self.fc21 = nn.Linear(1500, dim_z)
self.fc22 = nn.Linear(1500, dim_z)
self.fc3 = nn.Linear(dim_z, 1500)
self.fc4 = nn.Linear(1500, 45*45*3)
self.relu = nn.LeakyReLU()
def encode(self, x):
x = self.relu(self.fc1(x))
return self.fc21(x), self.fc22(x)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 *logvar)
eps = torch.randn_like(std)
return eps.mul(std).add_(mu)
def decode(self, z):
z = self.relu(self.fc3(z)) #1500
return torch.sigmoid(self.fc4(z))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
z = self.decode(z)
return z, mu, logvar
def loss_vae_fn(x, recon_x, mu, logvar):
BCE = F.binary_cross_entropy(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
model_vae = VAE().to(DEVICE)
def fit_epoch_vae(model, train_x, optimizer, batch_size, is_cnn=False):
running_loss = 0.0
processed_data = 0
for inputs in get_batch(train_x,batch_size):
inputs = inputs.view(-1, 45*45*3)
inputs = inputs.to(DEVICE)
optimizer.zero_grad()
decoded,mu,logvar, = model(inputs)
outputs = decoded.view(-1, 45*45*3)
outputs = outputs.to(DEVICE)
loss = loss_vae_fn(inputs,outputs,mu,logvar)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.shape[0]
processed_data += inputs.shape[0]
train_loss = running_loss / processed_data
return train_loss
def eval_epoch_vae(model, x_val, batch_size):
running_loss = 0.0
processed_data = 0
model.eval()
for inputs in get_batch(x_val,batch_size=batch_size):
inputs = inputs.view(-1, 45*45*3)
inputs = inputs.to(DEVICE)
with torch.set_grad_enabled(False):
decoded,mu,logvar = model(inputs)
outputs = decoded.view(-1, 45*45*3)
loss = loss_vae_fn(inputs,outputs,mu,logvar)
running_loss += loss.item() * inputs.shape[0]
processed_data += inputs.shape[0]
val_loss = running_loss / processed_data
#draw
with torch.set_grad_enabled(False):
pic = x_val[3]
pic_input = pic.view(-1, 45*45*3)
pic_input = pic_input.to(DEVICE)
decoded,mu,logvar = model(inputs)
pic_output = decoded[0].view(-1, 45*45*3).squeeze()
pic_output = pic_output.to("cpu")
pic_input = pic_input.to("cpu")
plot_gallery([pic_input, pic_output],45,45,1,2)
return val_loss
def train_vae(train_x, val_x, model, epochs=10, batch_size=32, lr=0.001):
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
history = []
log_template = "\nEpoch {ep:03d} train_loss: {t_loss:0.4f} val_loss: {val_loss:0.4f}"
with tqdm(desc="epoch", total=epochs) as pbar_outer:
for epoch in range(epochs):
train_loss = fit_epoch_vae(model,train_x,optimizer,batch_size)
val_loss = eval_epoch_vae(model,val_x,batch_size)
print("loss: ", train_loss)
history.append((train_loss,val_loss))
pbar_outer.update(1)
tqdm.write(log_template.format(ep=epoch+1, t_loss=train_loss, val_loss=val_loss))
return history
# history_vae = train_vae(X_train, X_val, model_vae, epochs=50, batch_size=128, lr=0.001)
# torch.save(history_vae,"vae_model.pth")
history_vae = torch.load("./tmp/variational-autoencoder-and-faces-generation/vae_model.pth")
train_loss, val_loss = zip(*history_vae)
plt.figure(figsize=(15,10))
plt.plot(train_loss, label='Train loss')
plt.plot(val_loss, label='Val loss')
plt.legend(loc='best')
plt.xlabel("epochs")
plt.ylabel("loss")
plt.plot();
42.108.11. Conclusion#
Variational autoencoders are cool. Although models in this particular notebook are simple they let us design complex generative models of data, and fit them to large datasets. They can generate images of fictional celebrity faces and high-resolution digital artwork. These models also yield state-of-the-art machine learning results in image generation and reinforcement learning. Variational autoencoders (VAEs) were defined in 2013 by Kingma et al. and Rezende et al.
42.108.12. Acknowledgments#
Thanks to SERGEI AVERKIEV for creating the Kaggle open-source project Variational Autoencoder and Faces Generation. It inspires the majority of the content in this chapter.