Data engineering
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet seaborn pandas scikit-learn numpy matplotlib jupyterlab_myst ipython
36. Data engineering#
Data engineering, also known as Information engineering, is a software engineering approach to designing and developing information systems. A data engineer is someone who creates big data ETL pipelines and makes it possible to take huge amounts of data and translate it into insights.
“Data is food for AI.” – Andrew Ng
Data engineering is critical where data is concerned, no matter whether it is for Machine Learning or not. Over the last decade, more and more companies have completed or are in progress with a digital transformation. This results in not only more data, but also the blooming of data-driven initiatives.
Even so, only 13% of data science projects actually were made into production, which is mentioned by IBM CTO Deborah Leff. Similarly, Gartner reiterated its prediction in 2019 that only 20% of analytic insights will deliver business outcomes through 2022. This is because the data is in unimaginable volumes, significantly complicated, and produced at a very high frequency. Therefore, data engineering becomes more and more important to play the role of organizing and ensuring the data’s quality, security, and availability for businesses.
Data Pipeline is usually the term used to describe a data engineering workflow consisting of one or more tasks that ingest, move, and transform raw data from one or more sources to a destination. But there is no golden standard to architect the process. For example, below are three different expressions of data pipeline structure in multiple layers.
Architecture: Ingestion, data Lake, preparation & computing, data warehouse, presentation
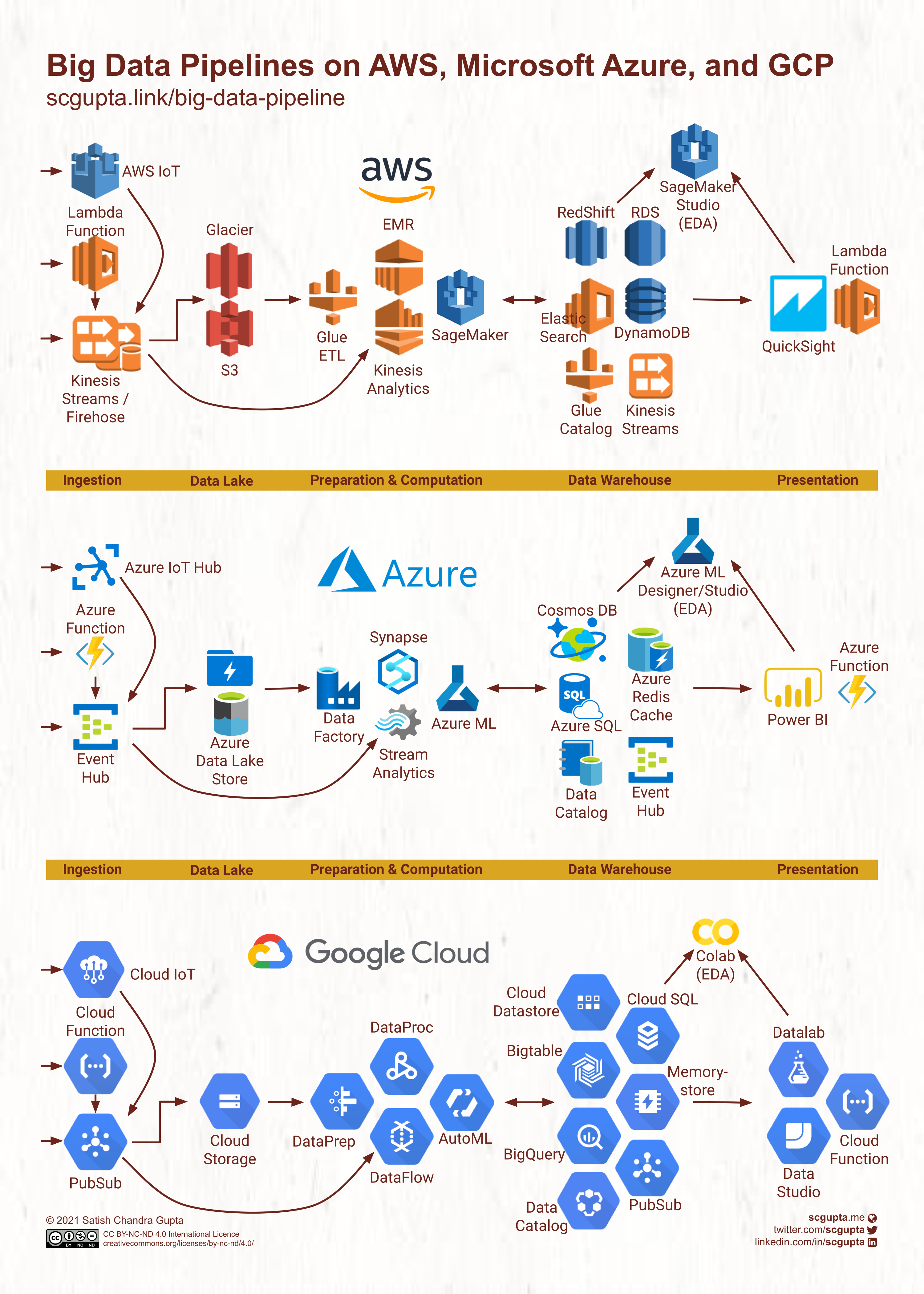
Fig. 36.1 Big Data Pipeline on AWS, Microsoft Azure, and Google Cloud#
Architecture: Capture, process, store, analyze, use
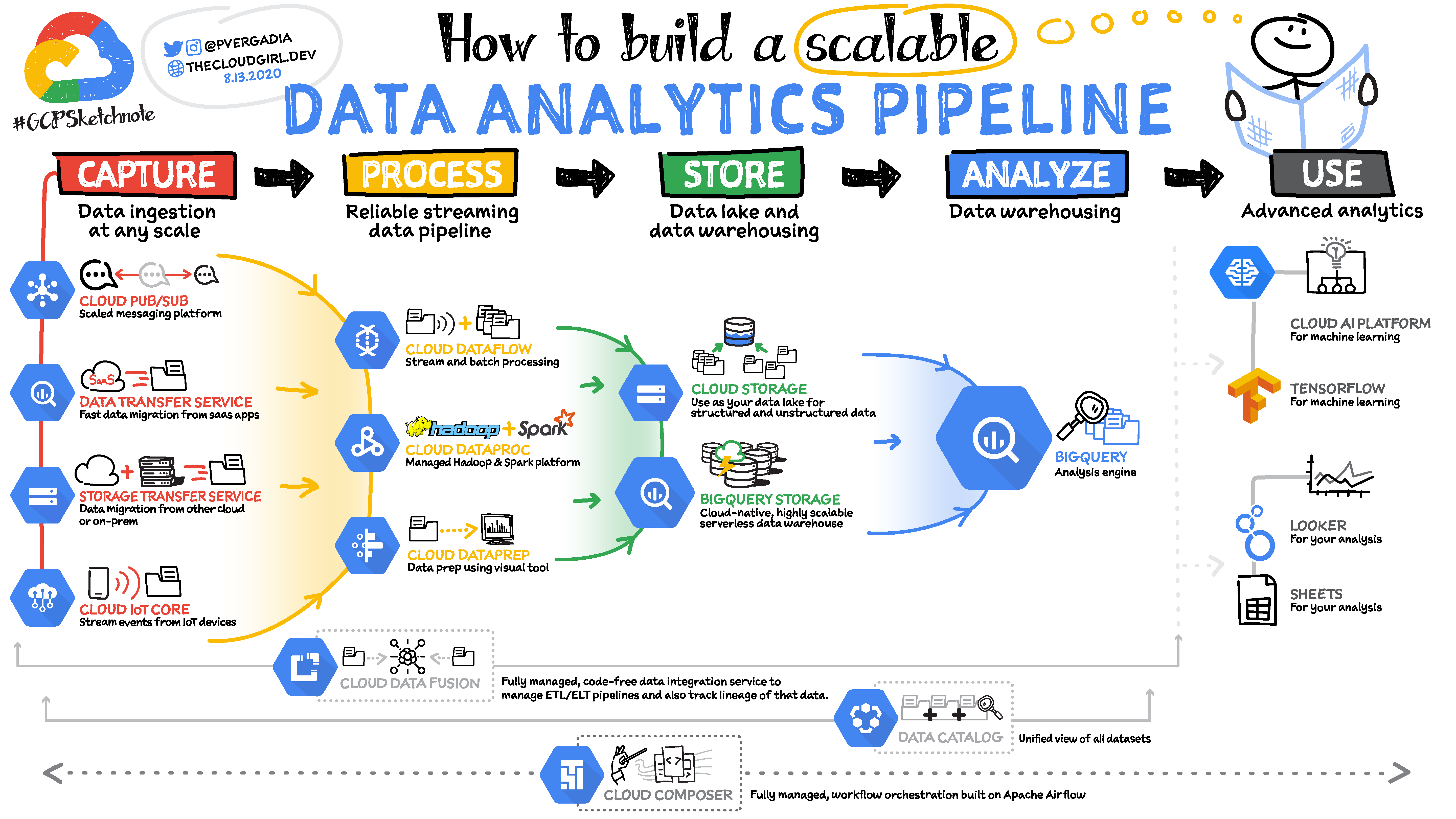
Fig. 36.2 How to build a Data Analytics Pipeline on Google Cloud?#
Ingestion, storage, cataloging & search, processing, consumption, security & governance
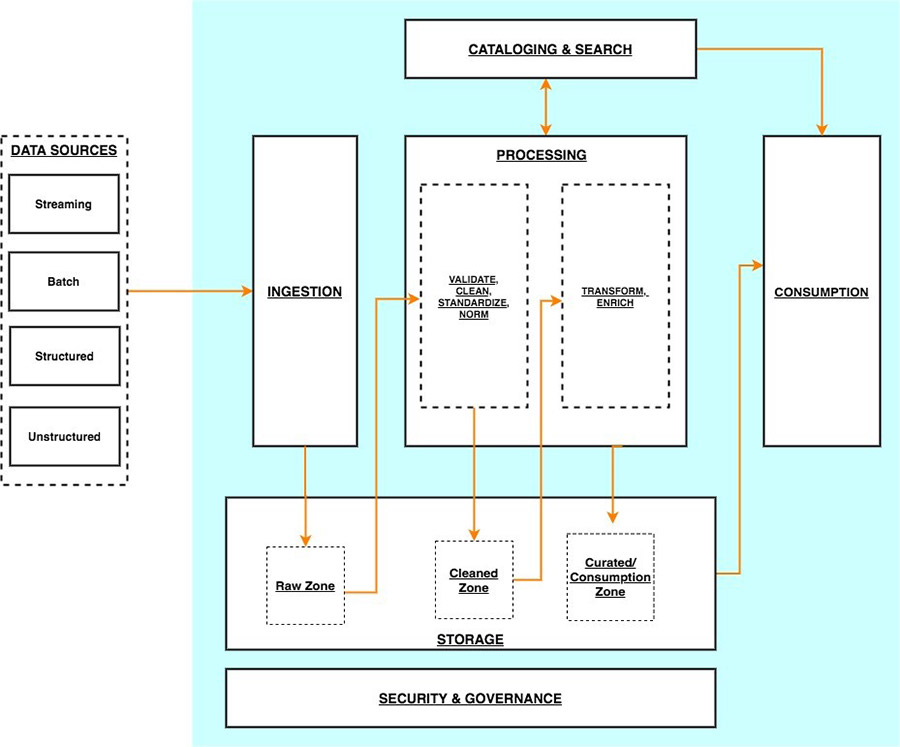
Fig. 36.3 AWS serverless data analytics pipeline#
In this section, the AWS serverless data analytics pipeline architecture above is used as a reference to breaking down the data pipeline into 6 layers. Before moving into each of them, we will first have a glance at the concept of data quality. And at the last, we will go through an AWS cloud-based data pipeline architecture showcase.
36.1. Data quality#
Data quality refers to the state of qualitative or quantitative pieces of information. Generally speaking, high-quality data could “fit for [its] intended uses in operations, decision making and planning”. Data quality is a widely used concept and is split into multiple dimensions traditionally. This section will discuss the most common ones to Machine Learning data engineering, including completeness, duplicates, outlier, and consistency.
See also
Data completeness. Most of the real-world datasets contain missing values, i.e.,
a product may not have an expiration date if it is from a category like cloth,
a survey may not contain data for some of the optional fields.
Missing a large portion of the datasets can break the Machine Learning model training and result in misleading inferences. As many Machine Learning algorithms do not have good support for missing values, it is important to detect the missing values and properly handle them.
Data duplicates can be in various formats, such as multiple entries of the same data, or repeated values of the identification variable. It not only wastes memory and computing resources but may also lead to data imbalance. Sometimes, duplicate data might be valid in a dataset, but it eventually still arises because of errors during data extraction and integration. Hence, it is important to identify if the duplicate values are intended or invalid values existing in the dataset.
Outlier is an observation that deviates so much from other observations as to arouse suspicion that it was generated by a different mechanism. It could be either the reflection of the dataset diversity itself or caused by errors and mistakes. Machine Learning algorithms are usually sensitive to the range and distribution of attribute values. Outliers may degrade the model performance by increasing the possibility to misclassify.
Data consistency. A dataset could be constructed from different data sources. For example, a retailer usually doesn’t have a centralized way to manage its supply chain. Instead, it achieves this by combining different ERP systems across demand, supply, shipment, inventory, and so on. Those ERP systems are vend from different software companies which have their solutions to structure and organize the data, e.g. to present timestamp as Unix epoch vs. the ISO format. Consistency data is necessary to build Machine Learning models. It is also important to help data scientists and business owners to have meaningful business analytics.
36.2. Ingestion layer#
Data ingestion is used to load data records from one or more sources, e.g. IoT devices, data lakes, databases, SaaS applications, etc., into a target data warehouse. It is the layer between the data source and data processing. Once ingested, the data becomes available in the data pipeline. There are three major ways to ingest data.
Batch ingestion, where the ingestion layer collects data from sources incrementally and sends it to the data storage in batch. Data can be grouped based on a schedule or certain rules. This approach is generally used for use cases that don’t require real-time data. And it is typically cost-effective and less expensive.
Stream ingestion is also known as real-time processing. Data are not grouped in any way and are directly sent to the data storage in real time once recognized. Applications that consume real-time data should use this way.
Micro batching ingestion is the approach used by streaming systems, such as Apache Spark Streaming. It divides data into small groups and ingests them incrementally as a stream. This makes the data more suitable for applications that have real-time data consumption requirements.
36.3. Storage layer#
The storage layer is responsible to provide durability, scalability, security, and cost-effectivity for big data storage. It supports storing both unstructured data and structured datasets in different formats. The data is usually loaded as-is without any processing to conform to a target format so that the ingestion layer could quickly land the source data into the storage. During processing, the data will be transformed from the original format to the one defined by the catalog layer, which is ready to be consumed downstream. To achieve the above, the storage layer could be organized into 3 different zones.
Raw data zone, which works as a transient area to store the ingested data from sources as-is.
Cleaned data zone, where data is only validated and cleaned, but still stored as original data format. This zone is necessary to support recovery, redo or rollback in case of the data processing is exceptionally exited or partially failed.
Processed data zone, where the ready-to-use data is stored in consumption-oriented format. Data here is fully processed by processing technologies, including cleaning, normalizing, standardizing, enriching, and so on. And typically the data in this zone is optimized to support cost-effective access, such as partitioned and cataloged.
36.4. Cataloging and search layer#
Once collected into the storage layer, the data needs to be cataloged and accessible to be actually usable in the remaining workflow, especially if the data volume is big. The cataloging and search layer is responsible to store metadata about datasets hosted in the storage layer, which is applied to business in the consumption layer and technical in the processing layer. It provides the ability to manage schema and makes datasets discoverable by providing search capabilities.
36.5. Processing layer#
The processing layer is responsible for transforming data to be consumable across the data storage zones, which includes multiple technologies such as data validation, cleanup, normalization, transformation, and enrichment. The processing layer needs to handle large data volumes with diverse data formats. The processing layer also provides the ability to build the processing workflow across the data storage zones, so that more complex processing logic could be better handled. Therefore, the processing layer could be composed of three types of components:
initializing component, which is used to create a multi-step data processing workflow on schedule or in response to event triggers,
orchestrating component, which manages the data processing workflow,
computing component, where the exact data processing programs are executed.
36.6. Consumption layer#
The consumption layer is responsible to provide scalable and performant tools to gain insights from the vast amount of data in the data storage. To achieve the best flexibility, this layer needs to support different types of data structures and formats, and use data partitioning to optimize cost and performance. The consumption layer is composed using analytics services, tools, and methods that enable:
interactive SQL to allow sending a SQL query to search and getting documents streamed back in response,
batch analytics to handle analytic workloads on big data datasets at the varying interval,
business intelligence to easily create and publish visualized dashboards for business insight analysis,
Machine Learning to support software applications to become more accurate at predicting outcomes by leveraging the data.
36.7. Security and governance layer#
The security and governance layer is responsible for protecting the data, identities, and processing resources across all other layers. It provides capabilities to manage the below aspects, including but not limited to below:
authentication and authorization to configure fine-grained access control for resources in all layers of the architecture,
encryption to create and manage symmetric and asymmetric customer-managed encryption keys,
network protection to choose the address range, create subnets, and configure route tables and network gateways,
monitoring and logging to analyze logs, visualize monitored metrics, define monitoring thresholds, and send alerts when thresholds.
36.8. Showcase#
Today, most of the main cloud providers offer their own serverless data pipeline solutions. They all target to enable agile and self-service data onboarding and analytics for the whole dataset, although are built on top of different cloud service stacks. By leveraging the data pipeline, engineers and scientists could focus more time on rapidly building data and analytics pipelines to drive insights for the business.
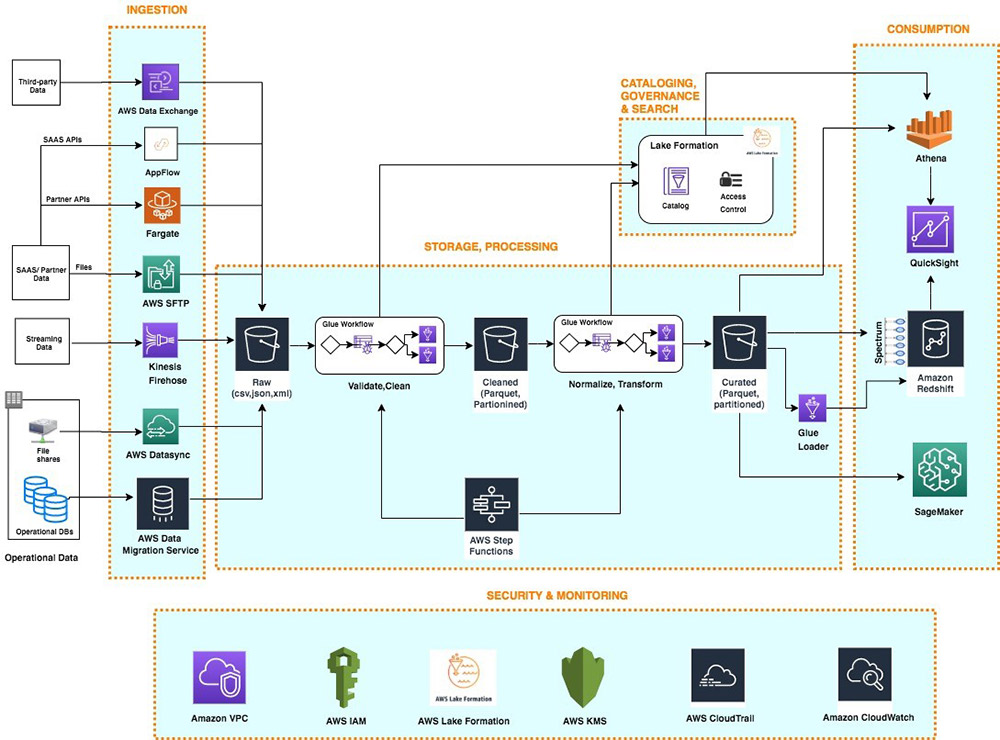
Fig. 36.4 Serverless data lake centric analytics architecture#
This diagram describes a reference architecture that uses AWS-managed services which compose the 6 layers mentioned in the above logical architecture. More specifically to this showcase:
AWS Data Migration Service and AWS Lake Formation are usually the options for database ingestion, while Amazon Kinesis Data Firehose is used for streaming data sources.
S3 is the foundation for the storage layer, and it provides more cost-effective colder-tier storage through Amazon S3 Glacier.
AWS Lake Formation is also the central place to store and manage metadata as the catalog for all datasets in the data lake.
AWS Glue and AWS Step Functions are serverless workflow services to build, orchestrate, and run pipelines.
To consume the processed data, plenty of products are available, such as Redshift, QuickSight, SageMaker, etc.
IAM, KMS, and CloudWatch are the most commonly used AWS services to provide governance capabilities globally.
If the pipeline is built on other cloud computing platforms, equivalent services could be easily found across all the layers. The architecture could also be simplified or customized according to the business needs.
36.9. Your turn! 🚀#
Data cleaning is a key part of data engineering to improve the data quality, but it can be deeply frustrating as the situation could be highly varied in different datasets. Sometimes you will see the text fields garbled. Sometimes your dates are formatted incorrectly. In this assignment, you’ll work through three hands-on exercises to deal with messy data.