Model deployment
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet seaborn pandas scikit-learn numpy matplotlib jupyterlab_myst ipython
38. Model deployment#
Jez Humble and David Farley define continuous delivery as the capacity to safely and efficiently introduce a wide range of changes, such as new features, configuration adjustments, bug fixes, and experiments, into production or the hands of users. Continuous delivery is a critical component for the automated production of high-quality software throughout the development pipeline. By emphasizing sustainable practices, Humble and Farley highlight the importance of ensuring that changes are made in a consistent and reliable manner.
Once the Machine Learning model is trained, it needs to be deployed as part of a business application such as a mobile or desktop application. The Machine Learning model requires various data points to produce predictions. The final stage of the Machine Learning workflow is the delivery of the previously engineered Machine Learning model into existing software.
The model deployment is a very challenging stage, as it needs to handle both traditional software challenges as well as Machine Learning specific challenges.
To the traditional software challenges, reliability is necessary to guarantee that the system could continue to work correctly performing inference at the desired level of performance. This is required even when the system faces hardware or software faults, and even human error. Maintainability is the key to allowing the system to be iterated productively over time in the collaborative work environment. With the team growing, flexibility and scalability become more and more important to deal with increased data volume, traffic volume, and complexity. Besides, the whole process must be under version control, through automated CI/CD pipelines and reusable in each development cycle.
Additionally, there are specific challenges for Machine Learning model deployment. The traditional continuous delivery must be extended to incorporate the Machine Learning based system. Besides the code, the model and the data could also be changed and delivered through the continuous process. So that updating Machine Learning models requires more thorough and thoughtful version control and more advanced CI/CD pipelines. For example, when a new version of the model is developed, the corresponding changes may need to be made not only to the model itself but also to the feature store or the data processing.

Fig. 38.1 The 3 axis of change in a Machine Learning application — data, model, and code — and a few reasons for them to change#
At last, Machine Learning development needs the coordination of scientists, software engineers, data engineers, and business professionals. This introduces extra challenges to ensure the model works reliably and delivers the desired result.
In this section, we will describe the important technical components for implementing Machine Learning model deployment, explain the concepts and demonstrate how different patterns can be used to implement the full end-to-end process.
38.1. Deployment strategies#
Deployment strategies are practices used to change or upgrade a running instance of an application.
Basic deployment implies that all nodes within a target environment (v1.0) are updated with a new version (v2.0) at the same time. This is the simplest but riskiest strategy because all the nodes will go down if the deployed artifacts are broken. This strategy also results in slow deployment rollback.
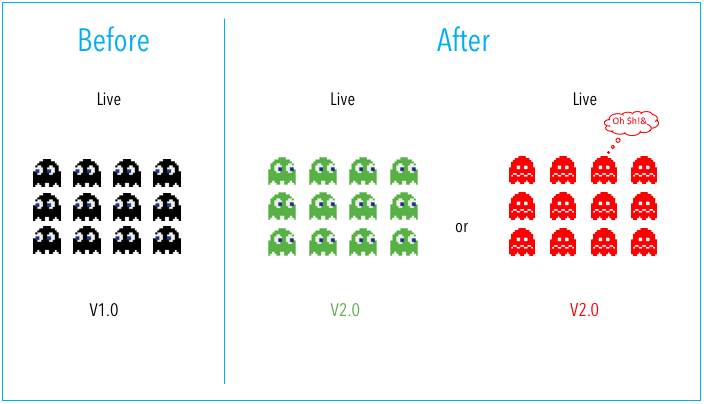
Fig. 38.2 Basic deployment strategy#
In practice, the real-world system is usually composed of many inter-depended modules or services. In this case, the multi-service deployment could be considered an option. To this strategy, all nodes within a target environment are updated with multiple new services simultaneously. This reduces the risk of system level failure but introduces the difficulty of managing the service dependencies in both deployment and rollback.
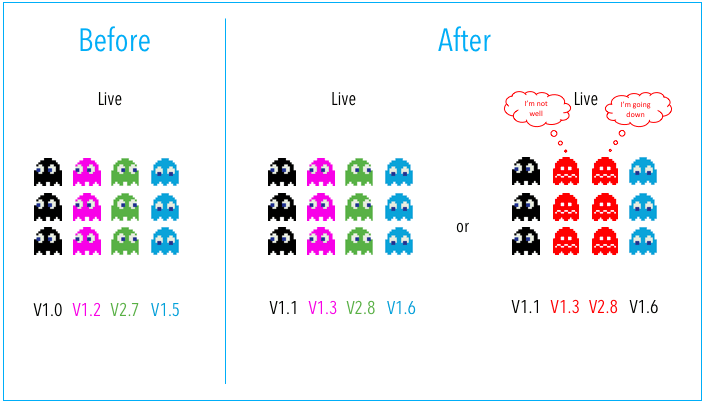
Fig. 38.3 Multi-service deployment strategy#
There are several options to help avoid the above issues. Rolling deployment incrementally updates all nodes in a target environment with the service or artifact version in batches. Canary development is similar but targets to roll out the new version to a certain subset of users instead of services. Both strategies could reduce the risk of failure by introducing finer granularity control to the deployment process. But they require services to support both new and old versions of an artifact, which make it more complex to manage the rollout and rollback.
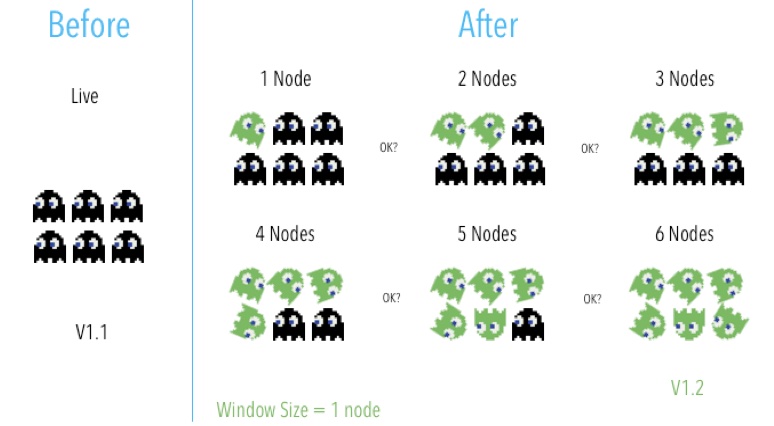
Fig. 38.4 Rolling deployment strategy#
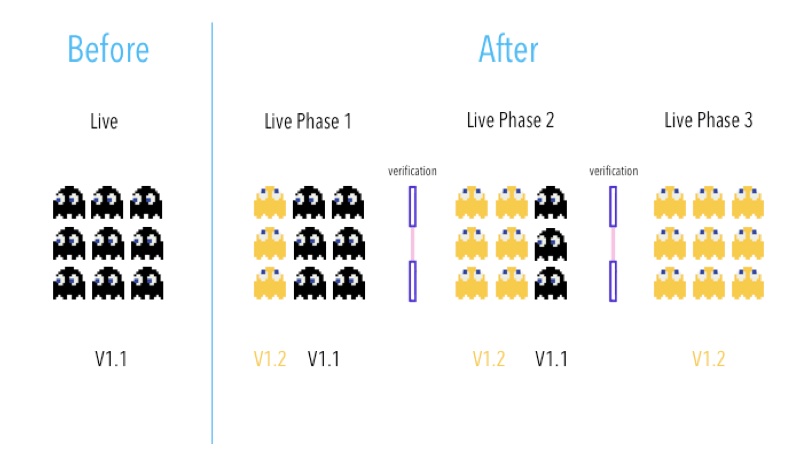
Fig. 38.5 Canary deployment strategy#
See also
When to use canary vs. Blue/green vs. Rolling deployment. (n.d.). SearchITOperations. Retrieved 11 August 2022
To further improve the deployment, Blue/Green strategy is the approach that utilizes two identical environments, a “blue” (aka staging) and a “green” (aka production) environment with different versions of an application or service. Testing is typically done within the blue environment that hosts new versions or changes. Once the new changes are approved, traffic could be shifted from the green environment to the blue one. After the deployment is finished, the blue environment then turns into the staging environment for the next round of deployment.
See also
When to use canary vs. Blue/green vs. Rolling deployment. (n.d.). SearchITOperations. Retrieved 11 August 2022
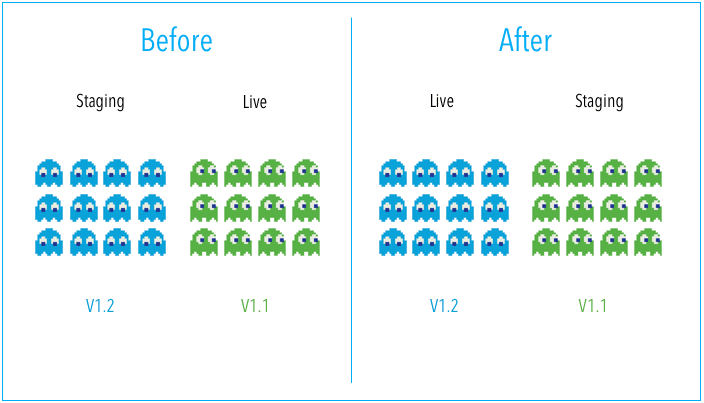
Fig. 38.6 Blue/Green deployment strategy#
38.2. Deployment evolution#
When computers were extremely large, expensive, and bulky, the software was often bundled together with the hardware by manufacturers. In the 1980s, new forms of software distribution, such as floppy disks and optical media, came together with the popularity of microcomputers, which meant the software deployment must be faster and more user-friendly. And since the internet age, agile software development has become possible. The advent of cloud computing and software as a service make software able to be deployed to a large number of customers in minutes over the internet.
As software development evolved, the determining factors of software deployment are changing as well. This requires the art-of-the-state deployment strategies and modes to provide better flexibility for modern computer applications.
Deployment 1.0
So-called deployment 1.0 is about deploying resources on-premises, which is an organization’s internal system along with the hardware and other infrastructure or also known as the private cloud. With the on-premises method, the deployment is under more control but takes more time to set up with more cost, although the CI/CD toolchain could help.
Deployment 1.0 usually has Machine Learning models built together with applications to simplify the infrastructure. But web server and the model inference code may be implemented in different programming languages, require different hardware resources, or be executed under different runtime environments. All of these may cause issues to the model deployment, and brings up the next level of deployment.
Deployment 2.0
Deployment 2.0 refers to the utilization of containers for software deployment. A container is a standardized software unit that encapsulates code and its dependencies, enabling the application to run consistently and efficiently across various computing environments. Google introduced containers in 2006, and Docker, which was launched in 2013, has become one of the most well-known container services
Containers provide a lightweight mechanism for isolating an application’s environment. But containers, even the machine running containers could be down still. If the service is consisted of multiple containers, the network failure could break the collaboration among them as well. As the system scales up, more sophisticated deployment strategies are needed to manage the load balance and rolling out and back.
Deployment 3.0
To address the concerns above, the container orchestration-based deployment is introduced to upgrade the deployment to 3.0. Container orchestration is to manage multiple containers and automates container lifecycle in large, dynamic environments. It allows taking advantage of the same environments for scaling quickly and easily. Kubernetes(K8s) is the most popular open-source orchestration system for automating the deployment, scaling, and management of containerized applications.
Kubernetes automates the deployment, scaling, and operations of application containers across clusters of hosts. It supports a broad range of container tools/infrastructures and works well with Docker. Kubernetes is inclusive to cloud providers like Cloud Native Computing Foundation(CNCF) and becomes the industry standard. The most popular IaaS providers also provide their container registries, which is especially useful for projects heavily invested in platforms like AWS, Azure, or Google Cloud.
Deployment 4.0
Machine Learning as a Service (MLaaS) refers to a range of cloud-based platforms that address infrastructure concerns associated with machine learning workflows. These platforms handle tasks such as data preprocessing, model training, model evaluation, and prediction. The prediction results can be seamlessly integrated with your internal IT infrastructure using REST APIs. Deployment 4.0 emphasizes the utilization of MLaaS for deploying machine learning solutions, making it a preferred choice when building a custom machine learning solution in-house.
Over the past years, several open-source frameworks have been developed for deploying Machine Learning services, such as Apache Airflow, KubeFLow, MLFlow, MetaFlow, etc. For example, Kubeflow is an open-source Machine Learning platform designed to orchestrate complicated Machine Learning workflows running on Kubernetes. It is the cloud-native platform providing both UI and SDK for Machine Learning operations including pipelines, training and deployment.
Besides, major public cloud players, such as Amazon, Azure, Google, and IBM, are all leading cloud MLaaS services that allow for fast model training and deployment. These open source toolkits are created and integrated closer with their original Machine Learning frameworks. Instead, the fully cloud-managed solutions are more neutral platforms that support more diverse Machine Learning environments and packages.
See also
The hitchhiker’s guide to the cloud (Aws vs gcp vs azure) and their ai/ml api’s capabilities. (n.d.). Retrieved 13 August 2022.
38.3. Serving#
It is crucial to clarify the intended experiments before deploying the trained models to users. This ensures that the models adhere to the constraints specified in the problem setup. What kind of feedback should be obtained from users? Should the model be updated online with every new data point? How can the model be personalized for individual users? How often should the Machine Learning algorithm be updated? Is there a possibility of biases and misuses in the model?
Regardless of which serving pattern to use, there is always an implicit contract between the model and users. The model will usually expect input data in a certain shape, and the changed model will require the contract to be updated for new input or add new features, which may cause integration issues and break the applications using it. Which leads the necessity of continuously monitoring and testing he model. However, to serve and use the model in production, there are a few patterns to achieve.
Model as module
This is the simpler approach, where the model works as a dependency that is built and packaged as a module together with the application itself. From this point forward, the application artifact and version could be treated as a combination of the application code and the Machine Learning model.
A simple way to serve the Machine Learning model embedded is to export it as a serialized pickle object. When building the application, we embed the model file inside the same Docker container and then get it versioned and deployed to production. There are other options to implement the this pattern. MLeap provides a common serialization format for exporting and importing models built by Spark, scikit-learn, and Tensorflow. There are also language-agnostic exchange formats to share models, such as PMML, PFA, and ONNX. Frameworks like H2O could support to export the Python or R implemented model as a compiled executable in another language, such a POJO in Java JAR.
Model as service
This is about to have the Machine Learning model to be wrapped in a service that can be deployed independently of the applications. This allows to update the model or the application independently. But it can also introduce more latency at inference time, as the model and the application are communicated with each other through remote invocation or service call for each prediction.
To implement the “model as service” pattern, most of the cloud providers have tools and SDKs to wrap the Machine Learning model for deployment into their MLaaS platforms, such as Azure Machine Learning, AWS Sagemaker, or Google AI Platform. Open-source solutions, such as Kubeflow for Machine Learning workflows on Kubernetes, could be used too, although they solve more than just the model serving.
Model as data
This is another approach to have the Machine Learning model treated and published independently, but the application will ingest it as data at runtime instead. This is more commonly used in streaming or real-time scenarios where the application can subscribe to events that are published whenever a new model version is released. The model data will be ingested into memory for predicting, which avoid introducing the extra latency. Deployment strategies such as Blue/Green deployment or Canary deployment can be applied in this scenario. Some of the above serialization options are also applicable for implementing the “model as data” pattern.
38.4. Infrastructure as code#
Infrastructure as code (IaC) is the process of managing and provisioning computer data centers through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools. The IT infrastructure managed by this process comprises both physical equipment, such as bare-metal servers, as well as virtual machines, and associated configuration resources.
GitHub Actions is one of the most well-known IaC implementations, although people may not treat it as IoC. Github Actions makes it easy to automate all the Github software workflows with CI/CD support. By leveraging Github Actions, the developer could manage any infrastructure tasks, including build, test, deploy as well as code reviews, branch management, and issue triaging. Below is some sample infrastructure code from Github Actions quickstart.
name: GitHub Actions Demo
on: [push]
jobs:
Explore-GitHub-Actions:
runs-on: ubuntu-latest
steps:
- run: echo "🎉 The job was automatically triggered by a ${{ github.event_name }} event."
- run: echo "🐧 This job is now running on a ${{ runner.os }} server hosted by GitHub!"
- run: echo "🔎 The name of your branch is ${{ github.ref }} and your repository is ${{ github.repository }}."
- name: Check out repository code
uses: actions/checkout@v3
- run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner."
- run: echo "🖥️ The workflow is now ready to test your code on the runner."
- name: List files in the repository
run: |
ls ${{ github.workspace }}
- run: echo "🍏 This job's status is ${{ job.status }}."
This sceipt will be triggered by a git code push, and runs on a ubuntu-latest instance. It first checks out the code repository by using action actions/checkout@v3, then lists all the files of the repository by running ls ${{ github.workspace }}.
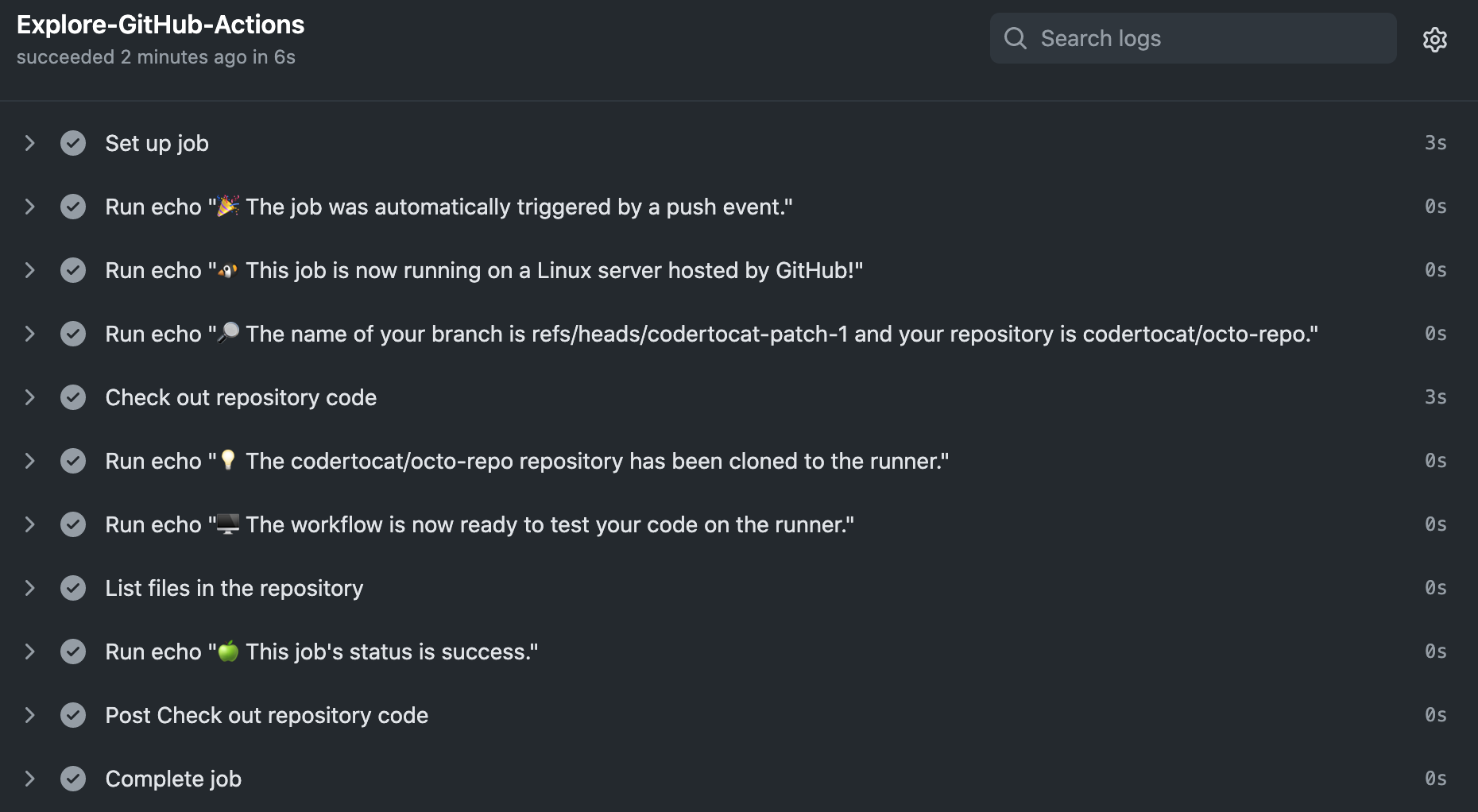
Fig. 38.7 Github Actions Quickstart Logs#
The log shows how each of the steps is processed. And, here is the list of files in the repository.
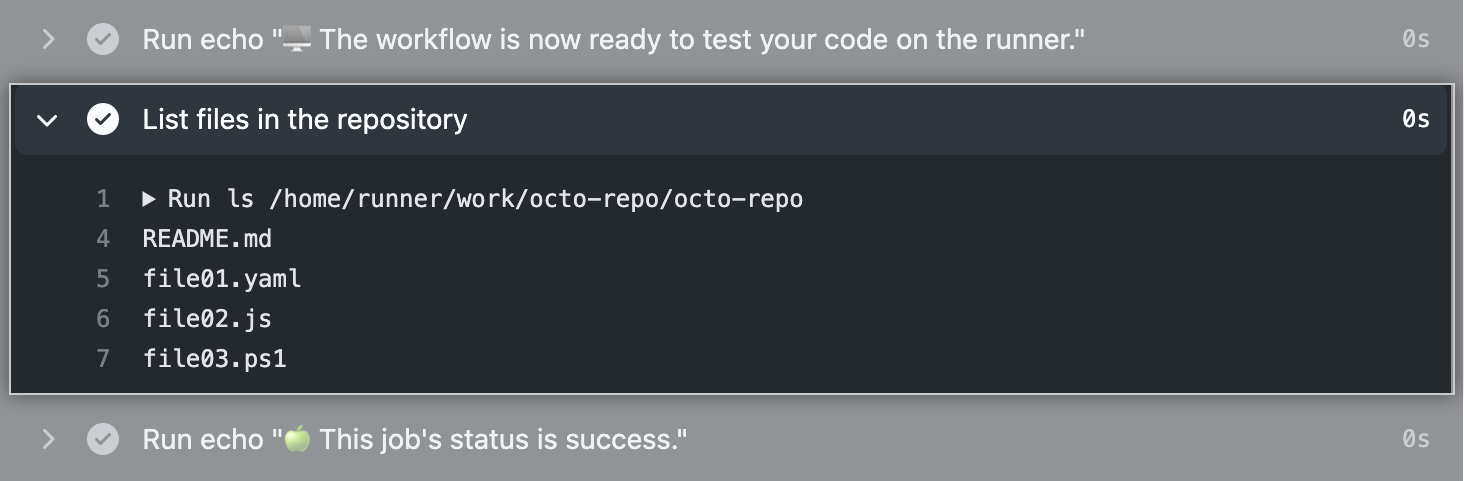
Fig. 38.8 Github Actions Quickstart Log Detail#
The RedHat-sponsored Ansible is an open-source IaC framework handling configuration management, application deployment, cloud provisioning, ad-hoc task execution, network automation, and multi-node orchestration. As a public cloud hosted solution, AWS CloudFormation is an IoC service that helps the development teams model and set up AWS resources so that they can spend less time managing those resources and more time focusing on the applications that run in AWS. Both the open-source and hosted frameworks altogeher provide the flexibility for development teams to choose the right solution to adopt based on their requirements.
38.5. Your turn! 🚀#
Practice the model serving by following this turorial.