Problem framing
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet seaborn pandas scikit-learn numpy matplotlib jupyterlab_myst ipython
35. Problem framing#
Problem framing is the process of analyzing a problem to isolate the individual elements that need to be addressed to solve it. It helps you to determine the feasibility of your project, and clearly defines the project goals and success criteria. Under our context, problem framing is to dive deep into the business requirements to figure out a potential Machine Learning based technical solution.
“Formal problem framing is the critical beginning for solving an ML problem, as it forces us to better understand both the problem and the data in order to design and build a bridge between them. “ – TensorFlow engineer
At a high level, Machine Learning problem framing consists of two distinct steps:
Determine if Machine Learning is the right approach to solve the problem.
Frame the problem in Machine Learning terms through the whole development lifecycle.
Before rushing into the Machine Learning implementation, let’s frame the problem by answering the below questions first.
35.1. Is Machine Learning the best choice?#
Machine Learning is not universally applicable. Similar to any other technology, it could only be used to solve certain problems.
What are the existing solutions? Machine Learning may be considered either when a problem is new, or existing non-Machine Learning solutions are not optimized. If it is the former, try solving the problem manually using a heuristic approach. Otherwise, the existing non-Machine Learning solution could be leveraged as a benchmark to help you make the decision.
Is the error tolerable? Achieving 100% accuracy in Machine Learning predictions is challenging. Occasionally, the slight possibility of false negatives may be unacceptable. Consider Deep Learning’s success in expediting MRI reconstruction compared to conventional methods. Despite the significant enhancement in image quality, the issue of false-negative reconstructions persists and warrants improvement.
Is concrete interpretability needed? Machine learning effectively enhances products, processes, and research, yet computers typically do not articulate their reasoning. The potential issue of the dark secret at the heart of AI may arise. Conversely, improved explanations could bolster trust in the decision to embrace machine learning. However, this remains a challenge, especially in the context of supervised machine learning, not to mention deep learning.
Any risk to violate ethics or regulation? AI raises significant ethical concerns for society, particularly in the areas of privacy and surveillance, bias, and discrimination. For instance, in the heavily regulated banking industry, algorithm-based lending decisions could lead to systematic discrimination against African Americans and other marginalized consumers.
Are any Machine Learning approaches available? To create a TikTok alike short video platform, Amazon Rekognition could help build AI-powered content moderation easily. And Amazon Transcribe is something ready to use for generating transcripts automatically for customers. To reinvent the wheel is resource-wasting and should be avoided always.
Is Machine Learning cost-effective? The expenses associated with a Machine Learning solution may span various areas, similar to traditional software development, such as cloud services, data, hardware, human resources, maintenance, and more. Additionally, if the team lacks experience in Machine Learning, the additional training costs should be taken into account. When considering Machine Learning as an option, the concept of opportunity cost must be kept in mind. Specifically, the application of machine learning can easily lead to significant ongoing maintenance costs at the system level, including boundary erosion, entanglement, hidden feedback loops, undisclosed consumers, data dependencies, changes in the external environment, and various system-level antipatterns.
See also
Sculley, David, et al. “Hidden technical debt in machine learning systems.” Advances in neural information processing systems 28 (2015).
35.2. How easy to obtain the data?#
It is no doubt that data is the driving force of Machine Learning. Make sure you have the data required to train a model, before initiating the Machine Learning execution. Regardless of the challenge to gather data from your own company or real customers, the options below could be helpful.
Synthetic data, referring to any production data relevant to a given situation that is not obtained through direct measurement, is typically generated by computer simulation. In today’s AI landscape, synthetic data is increasingly gaining importance and is even projected to surpass real data by 2030 (Gartner Inc.). Generative Adversarial Networks(GANs) stand out as one of the most popular frameworks for generating synthetic data. For instance, Ford has combined gaming engines and GANs to create synthetic data for AI training for self-driving. Other approaches to generating synthetic data include statistical distribution fitting, rule-based procedural generation, benchmarks, simulations, and more.
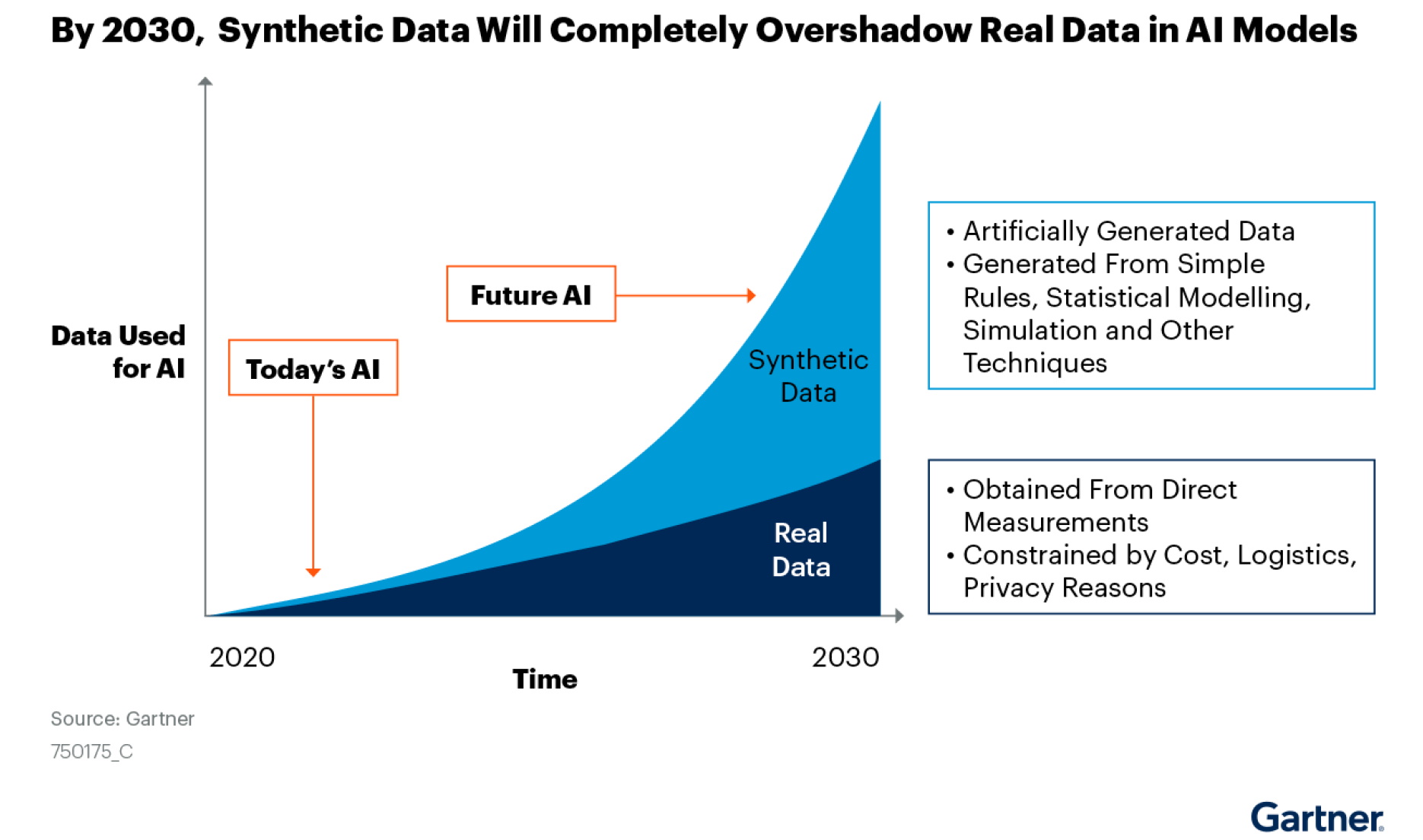
Fig. 35.1 Synthetic Data Will Completely Overshadow Real Data in AI Models(https://www.gartner.com/en/documents/4002912)#
See also
El Emam, Khaled, Lucy Mosquera, and Richard Hoptroff. Practical synthetic data generation: balancing privacy and the broad availability of data. O’Reilly Media, 2020.
Public data. There are many public available Open Source or free-to-use datasets. They are on plenty of different topics, easy to access, and of good quality. data.gov is a great example of the government entity. The White House under the Obama administration has been a leader in its approach to transparency and launched the website in 2009. To date, more than 300k datasets are available on the site.
See also
Open Learning Resource - dataset - a curated list of open-source/public datasets.
More data is better? The question of whether more data is better has both a yes and no answer. Research has shown that the performance of Machine Learning can increase either monotonically (Banko and Brill, 2001) or logarithmically (Halevy et al., 2009) based on the volume of training data, suggesting that in general, more data is beneficial. However, this is not universally true, as the introduction of more data can also lead to increased noise, which may diminish the quality of the data. Additionally, the availability of large public datasets such as Imagenet and recent advancements in research have reduced the competitive advantage of having access to more data. Therefore, while more data can be advantageous, it is not always the case, and the quality of the data is equally important.
35.3. What models to use?#
This is one of the most widely discussed topics when people approach a Machine Learning solution. There are three main categories of machine learning: supervised learning, unsupervised learning, and reinforcement learning. The cheat sheet from Microsoft could be a helpful quick reference.
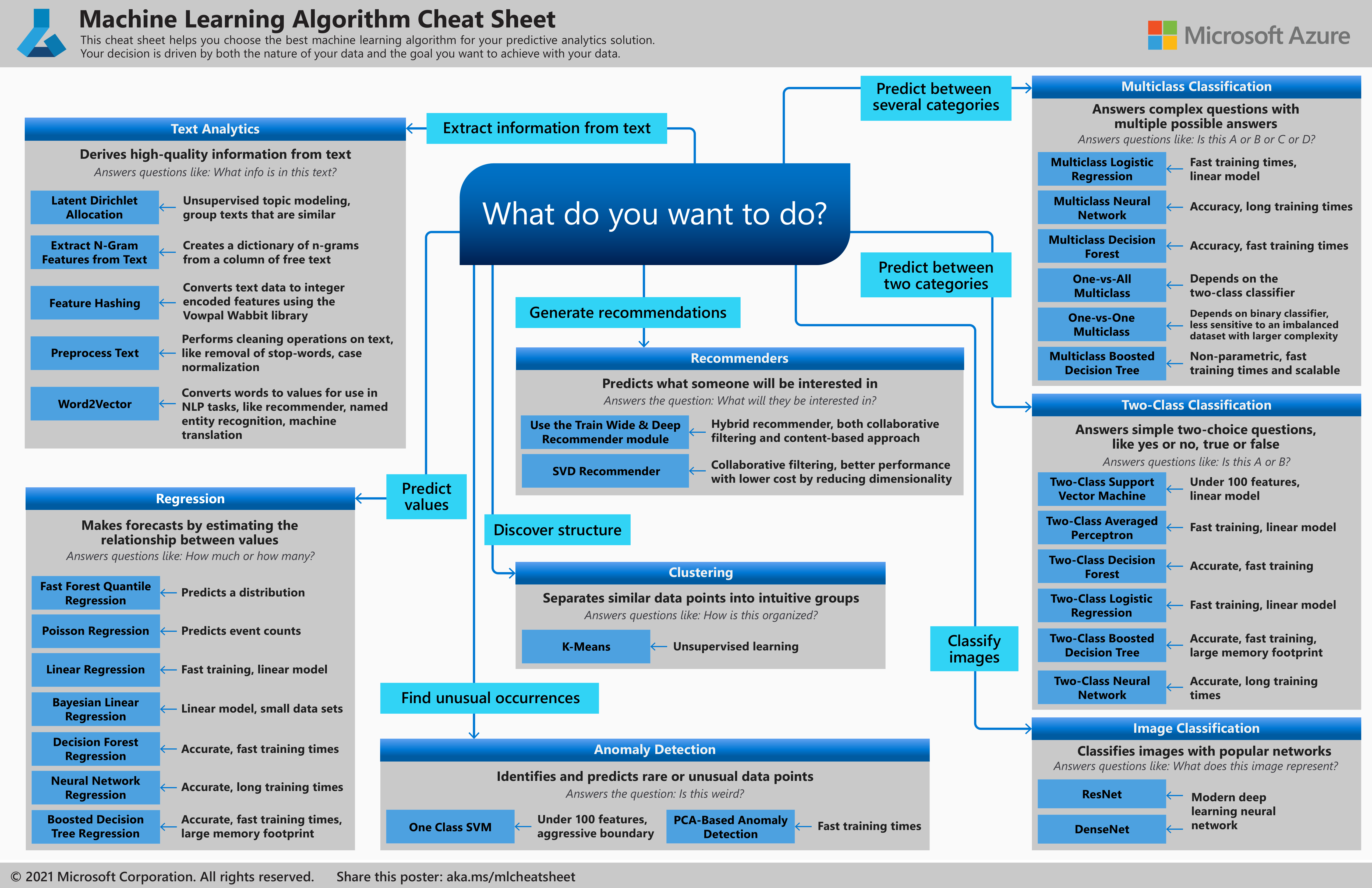
Fig. 35.2 Machine Learning Algorithm Cheat Sheet#
See also
Automated Machine Learning (AutoML) is the process and method of automating the tasks of applying Machine Learning to real-world problems, which is another option to help select the algorithm. It makes Machine Learning available to non-experts, such as software engineers. Many open-source libraries could be leveraged for AutoML, such as AutoGluon, AutoKeras.
35.4. How to put a model into production?#
Machine Learning inference is the process of inputting data into a model to calculate an output, which is also referred to as “putting a Machine Learning model into production”. There are two major types of inferences that may impact the feasibility of productionize the trained model.
Batch inference means that multiple predictions are requested periodically. The COVID-19 Projections project is typically a batch inference example, which is mentioned in the previous section. Another good example is Facebook News feed generation, which is a complex and time-consuming artificial intelligent process. The News feeds are pre-generated regularly and stored in the cache. Then the web application could request and present the cached feeds in runtime.
Online inference, on the contrary, is the process to handle the prediction in real-time, synchronized, or from continuous data streaming. The online inference is suitable for more latency-sensitive user scenarios such as search engines and autonomous driving. And it requires speeding up both the inferring and input data sampling. It should be noted that the inference is usually just part of the end-to-end workflow of serving a request from the client side. It will be more challenging if the reference is on the critical path.
35.5. Your turn! 🚀#
Apply the knowledge of this section to refine your own Machine Learning project proposal.