Complete the transformer architecture
Contents
42.130. Complete the transformer architecture#
# set up the env
import pytest
import ipytest
import unittest
ipytest.autoconfig()
42.130.1. Transformer Model#
The encoder-decoder architecture based on the Transformer structure is illustrated in figure below. The left and right sides correspond to the encoder and decoder structures, respectively. They consist of several basic Transformer blocks (represented by the gray boxes in the figure), stacked N times. Each component comprises multiple Transformer blocks, which are stacked N times.
Here’s an overview of the key components and processes involved in the semantic abstraction process from input to output:
Encoder:
The encoder takes an input sequence {xi}ti=1, where each xi represents the representation of a word in the text sequence. It consists of stacked Transformer blocks. Each block includes: Attention Layer: Utilizes multi-head attention mechanisms to capture dependencies between words in the input sequence, facilitating the modeling of long-range dependencies without traditional recurrent structures. Position-wise Feedforward Layer: Applies complex transformations to the representations of each word in the input sequence. Residual Connections: Directly connect the input and output of the attention and feedforward layers, aiding in efficient information flow and model optimization. Layer Normalization: Normalizes the output representations of the attention and feedforward layers, stabilizing optimization. Decoder:
The decoder generates an output sequence {yi}ti=1 based on the representations learned by the encoder. Similar to the encoder, it consists of stacked Transformer blocks, each including the same components as described above. In addition, the decoder includes an additional attention mechanism that focuses on the encoder’s output to incorporate context information during sequence generation. Overall, the encoder-decoder architecture based on the Transformer structure allows for effective semantic abstraction by leveraging attention mechanisms, position-wise feedforward layers, residual connections, and layer normalization. This architecture enables the model to capture complex dependencies between words in the input sequence and generate meaningful outputs for various sequence-to-sequence tasks.
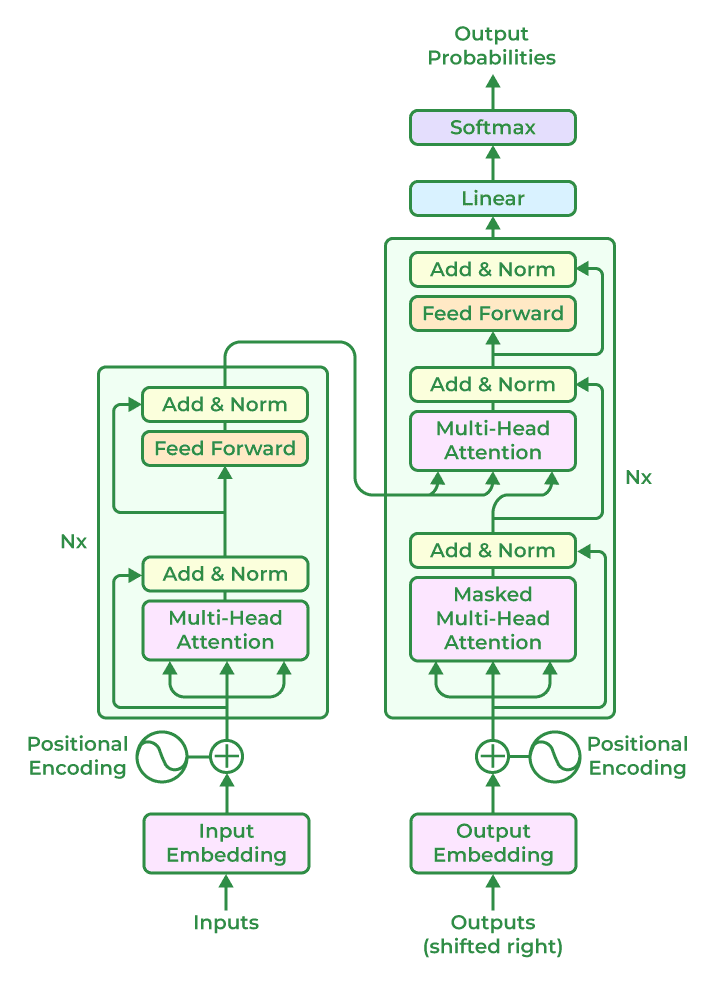
Fig. 42.1 Transformer-based encoder and decoder Architecture#
Next, we’ll discuss the specific functionalities and implementation methods of each module in detail.
42.130.2. Embedding Layer#
The Embedding Layer in the Transformer model is responsible for converting discrete token indices into continuous vector representations. Each token index is mapped to a high-dimensional vector, which is learned during the training process. These embeddings capture semantic and syntactic information about the tokens.
Implementation in PyTorch:
We define a PositionalEncoder class that inherits from nn.Module. The constructor initializes the positional encoding matrix (pe) based on the given d_model (dimension of the model) and max_seq_len (maximum sequence length). The forward method scales the input embeddings (x) by the square root of the model dimension and adds the positional encoding matrix (pe) to the input embeddings. Note that we’re using PyTorch’s Variable and autograd to ensure that the positional encoding is compatible with the autograd mechanism for backpropagation. Finally, the PositionalEncoder class can be used within a larger PyTorch model to incorporate positional information into word embeddings.
import torch
import torch.nn as nn
import math
import copy
import time
import torch.optim as optim
import torch.nn.functional as F
from torch.autograd import Variable
import numpy as np
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len=80):
super().__init__()
self.d_model = d_model
# Creating a constant PE matrix based on pos and i
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i) / d_model)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1)) / d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# Scaling word embeddings to make them relatively larger
x = x * math.sqrt(self.d_model)
# Adding positional constants to word embedding representations
seq_len = x.size(1)
x = x + Variable(self.pe[:, :seq_len], requires_grad=False).cuda()
Check result by executing below... 📝
%%ipytest -qq
class TestPositionalEncoder(unittest.TestCase):
def setUp(self):
self.d_model = 512
self.max_seq_len = 10 # Maximum sequence length for testing
self.positional_encoder = PositionalEncoder(self.d_model, self.max_seq_len)
def test_forward(self):
# Create a sample input tensor representing word embeddings
batch_size = 2
seq_length = 5
word_embeddings = torch.randn(batch_size, seq_length, self.d_model)
# Forward pass through the PositionalEncoder module
output = self.positional_encoder(word_embeddings)
# Check if the output shape matches the input shape
assert output.shape == (batch_size, seq_length, self.d_model)
# Check if positional encoding is correctly applied
# Example: Verify if the first element of the first embedding vector matches the expected value
expected_first_element = torch.sin(torch.tensor([0.0])) * math.sqrt(self.d_model)
assert math.isclose(output[0, 0, 0].item(), expected_first_element.item(), rel_tol=1e-6)
42.130.3. Attention Layer#
The Attention Layer in the Transformer model enables the model to focus on different parts of the input sequence when processing each token. It computes attention scores between each pair of tokens in the input sequence and generates a context vector for each token based on the importance of other tokens. This mechanism allows the model to capture long-range dependencies in the input sequence effectively.
Implementation in PyTorch:
The MultiHeadAttention class defines a multi-head self-attention layer. The forward method performs linear operations to divide inputs into multiple heads, computes attention scores, and aggregates the outputs of multiple heads.
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout=0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads
self.h = heads
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model)
def attention(self, q, k, v, d_k, mask=None, dropout=None):
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
# Masking out those units added for length padding, setting them to zero after softmax computation
if mask is not None:
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
scores = F.softmax(scores, dim=-1)
if dropout is not None:
scores = dropout(scores)
output = torch.matmul(scores, v)
return output
def forward(self, q, k, v, mask=None):
bs = q.size(0)
# Linear operations to divide into h heads
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# Matrix transposition
k = k.transpose(1, 2)
q = q.transpose(1, 2)
v = v.transpose(1, 2)
# Computing attention
scores = self.attention(q, k, v, self.d_k, mask, self.dropout)
# Concatenating multiple heads and feeding into the final linear layer
concat = scores.transpose(1, 2).contiguous().view(bs, -1, self.d_model)
output = self.out(concat)
return output
Check result by executing below... 📝
%%ipytest -qq
class TestMultiHeadAttention(unittest.TestCase):
def test_forward(self):
# Instantiate MultiHeadAttention module
heads = 4
d_model = 64
dropout = 0.1
multihead_attn = MultiHeadAttention(heads, d_model, dropout)
# Create sample input tensors
batch_size = 2
seq_length = 5
q = torch.randn(batch_size, seq_length, d_model)
k = torch.randn(batch_size, seq_length, d_model)
v = torch.randn(batch_size, seq_length, d_model)
mask = torch.randint(0, 2, (batch_size, 1, seq_length)) # Example mask tensor
# Forward pass through the MultiHeadAttention module
output = multihead_attn(q, k, v, mask)
# Check output shape
self.assertEqual(output.shape, (batch_size, seq_length, d_model))
42.130.4. Feedforward Layer#
The Position-wise Feedforward Layer in the Transformer model applies a simple feedforward neural network independently to each position in the sequence. It consists of two linear transformations with a non-linear activation function (commonly ReLU) applied in between. This layer helps capture complex interactions between different dimensions of the input embeddings.
Implementation in PyTorch:
The FeedForward class defines a feedforward layer. The forward method applies ReLU activation to the output of the first linear transformation, followed by dropout, and then performs the second linear transformation to produce the final output.
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout=0.1):
super().__init__()
# Setting d_ff default to 2048
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)
return x
Check result by executing below... 📝
%%ipytest -qq
class TestFeedForward(unittest.TestCase):
def test_forward(self):
# Instantiate FeedForward module
d_model = 512
d_ff = 2048
dropout = 0.1
feed_forward = FeedForward(d_model, d_ff, dropout)
# Create sample input tensor
batch_size = 2
seq_length = 5
input_tensor = torch.randn(batch_size, seq_length, d_model)
# Forward pass through the FeedForward module
output = feed_forward(input_tensor)
# Check output shape
self.assertEqual(output.shape, (batch_size, seq_length, d_model))
42.130.5. Residual Connection and Layer Normalization#
Residual Connection: The Residual Connection, also known as skip connection, is a technique used in deep neural networks to mitigate the vanishing gradient problem and facilitate the flow of information through the network. In the context of the Transformer model, residual connections are added around each sub-layer (such as attention and feedforward layers) before applying layer normalization. This allows the model to learn residual representations and thus ease the optimization process.
Layer Normalization: Layer Normalization is a technique used to stabilize the training of deep neural networks by normalizing the activations of each layer. In the Transformer model, layer normalization is applied after each sub-layer (such as attention and feedforward layers) and before the residual connection. It normalizes the activations along the feature dimension, allowing the model to learn more robust representations and accelerate convergence during training.
Implementation in PyTorch:
The NormLayer class defines a layer normalization layer. The forward method computes the layer normalization using the given input tensor x.
class NormLayer(nn.Module):
def __init__(self, d_model, eps=1e-6):
super().__init__()
self.size = d_model
# Layer normalization includes two learnable parameters
self.alpha = nn.Parameter(torch.ones(self.size))
self.bias = nn.Parameter(torch.zeros(self.size))
self.eps = eps
def forward(self, x):
norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \
/ (x.std(dim=-1, keepdim=True) + self.eps) + self.bias
return norm
Check result by executing below... 📝
%%ipytest -qq
class TestNormLayer(unittest.TestCase):
def test_forward(self):
# Instantiate NormLayer module
d_model = 512
eps = 1e-6
norm_layer = NormLayer(d_model, eps)
# Create sample input tensor
batch_size = 2
seq_length = 5
input_tensor = torch.randn(batch_size, seq_length, d_model)
# Forward pass through the NormLayer module
output = norm_layer(input_tensor)
# Check output shape
self.assertEqual(output.shape, (batch_size, seq_length, d_model))
42.130.6. Encoder and Decoder Structure#
Encoder Structure: The Encoder in the Transformer model consists of multiple stacked Encoder layers. Each Encoder layer typically contains a Multi-Head Attention sub-layer followed by a FeedForward sub-layer, each with Residual Connection and Layer Normalization.
Decoder Structure: Similarly, the Decoder in the Transformer model also consists of multiple stacked Decoder layers. Each Decoder layer contains three sub-layers:
Masked Multi-Head Attention sub-layer to attend to previous tokens in the output sequence. Multi-Head Attention sub-layer that attends to the encoder’s output. FeedForward sub-layer. Again, each sub-layer is followed by Residual Connection and Layer Normalization.
Below are the Python implementations for the Encoder and Decoder structures:
The EncoderLayer and DecoderLayer classes define encoder and decoder layers, respectively. The Encoder and Decoder classes define encoder and decoder modules, respectively, composed of multiple layers of encoder or decoder layers. These classes follow the architecture described in the text, including the use of multi-head attention, feedforward layers, residual connections, and layer normalization.
class Embedder(nn.Module):
def __init__(self, vocab_size, d_model):
super(Embedder, self).__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.d_model = d_model
def forward(self, x):
return self.embed(x) * np.sqrt(self.d_model)
def get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
class PositionalEncoder(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoder, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
class EncoderLayer(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm_1 = NormLayer(d_model)
self.norm_2 = NormLayer(d_model)
self.attn = MultiHeadAttention(heads, d_model, dropout=dropout)
self.ff = FeedForward(d_model, dropout=dropout)
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x, mask):
x2 = self.norm_1(x)
x = x + self.dropout_1(self.attn(x2, x2, x2, mask))
x2 = self.norm_2(x)
x = x + self.dropout_2(self.ff(x2))
return x
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, dropout=dropout)
self.layers = get_clones(EncoderLayer(d_model, heads, dropout), N)
self.norm = NormLayer(d_model)
def forward(self, src, mask):
x = self.embed(src)
x = self.pe(x)
for i in range(self.N):
x = self.layers[i](x, mask)
return self.norm(x)
class DecoderLayer(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm_1 = NormLayer(d_model)
self.norm_2 = NormLayer(d_model)
self.norm_3 = NormLayer(d_model)
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
self.dropout_3 = nn.Dropout(dropout)
self.attn_1 = MultiHeadAttention(heads, d_model, dropout=dropout)
self.attn_2 = MultiHeadAttention(heads, d_model, dropout=dropout)
self.ff = FeedForward(d_model, dropout=dropout)
def forward(self, x, e_outputs, src_mask, trg_mask):
x2 = self.norm_1(x)
x = x + self.dropout_1(self.attn_1(x2, x2, x2, trg_mask))
x2 = self.norm_2(x)
x = x + self.dropout_2(self.attn_2(x2, e_outputs, e_outputs, src_mask))
x2 = self.norm_3(x)
x = x + self.dropout_3(self.ff(x2))
return x
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, dropout=dropout)
self.layers = get_clones(DecoderLayer(d_model, heads, dropout), N)
self.norm = NormLayer(d_model)
def forward(self, trg, e_outputs, src_mask, trg_mask):
x = self.embed(trg)
x = self.pe(x)
for i in range(self.N):
x = self.layers[i](x, e_outputs, src_mask, trg_mask)
return self.norm(x)
The overall implementation of the Transformer encoder and decoder structure:
class Transformer(nn.Module):
def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)
self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)
self.out = nn.Linear(d_model, trg_vocab)
def forward(self, src, trg, src_mask, trg_mask):
e_outputs = self.encoder(src, src_mask)
d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)
output = self.out(d_output)
return output
The training process for the Transformer model:
# Sample English and French text data
en_data = [
"I love coding.",
"Machine learning is fascinating.",
"Natural language processing is fun."
]
fr_data = [
"J'adore coder.",
"L'apprentissage automatique est fascinant.",
"Le traitement du langage naturel est amusant."
]
def tokenize_en(sentence):
# You can implement a more sophisticated tokenizer here if needed
return sentence.lower().split() # Simple tokenizer, converts to lowercase and splits by space
def tokenize_fr(sentence):
# You can implement a more sophisticated tokenizer here if needed
return sentence.lower().split() # Simple tokenizer, converts to lowercase and splits by space
# Tokenize English and French text
en_sentences = [tokenize_en(sentence) for sentence in en_data]
fr_sentences = [tokenize_fr(sentence) for sentence in fr_data]
# Create English and French vocabularies
en_vocab = {'<pad>': 0, '<sos>': 1, '<eos>': 2, '<unk>': 3} # Initialize with special tokens
fr_vocab = {'<pad>': 0, '<sos>': 1, '<eos>': 2, '<unk>': 3} # Initialize with special tokens
# Build English vocabulary
for sentence in en_sentences:
for word in sentence:
if word not in en_vocab:
en_vocab[word] = len(en_vocab)
# Build French vocabulary
for sentence in fr_sentences:
for word in sentence:
if word not in fr_vocab:
fr_vocab[word] = len(fr_vocab)
# Reverse vocabularies to get index-to-token mappings
en_index_to_word = {index: word for word, index in en_vocab.items()}
fr_index_to_word = {index: word for word, index in fr_vocab.items()}
# Model parameters
d_model = 512
heads = 8
N = 6
src_vocab = len(en_vocab)
trg_vocab = len(fr_vocab)
dropout = 0.1
# Initialize the model
model = Transformer(src_vocab, trg_vocab, d_model, N, heads, dropout)
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
# Optimizer
optim = torch.optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
# Training the model
def train_model(epochs, en_sentences, fr_sentences, print_every=100):
model.train()
start = time.time()
temp = start
total_loss = 0
for epoch in range(epochs):
for i in range(len(en_sentences)):
src_sentence = en_sentences[i]
trg_sentence = fr_sentences[i]
src_tensor = torch.LongTensor([en_vocab[word] for word in src_sentence])
trg_tensor = torch.LongTensor([fr_vocab[word] for word in trg_sentence])
src = src_tensor.unsqueeze(0) # Add batch dimension
trg = trg_tensor.unsqueeze(0) # Add batch dimension
trg_input = trg[:, :-1]
targets = trg[:, 1:].contiguous().view(-1)
src_mask, trg_mask = create_masks(src, trg_input)
preds = model(src, trg_input, src_mask, trg_mask)
optim.zero_grad()
loss = F.cross_entropy(preds.view(-1, preds.size(-1)), targets, ignore_index=fr_vocab['<pad>'])
loss.backward()
optim.step()
total_loss += loss.item()
if (i + 1) % print_every == 0:
loss_avg = total_loss / print_every
print("time = %dm, epoch %d, iter = %d, loss = %.3f, %ds per %d iters" % ((time.time() - start) // 60, epoch + 1, i + 1, loss_avg, time.time() - temp, print_every))
total_loss = 0
temp = time.time()
train_model(1000, en_sentences, fr_sentences, 100)
Test the trained model:
# Test the model
def translate(model, src_sentence, en_vocab, fr_vocab, max_len=80):
model.eval()
# Tokenize the source sentence
src_tokens = tokenize_en(src_sentence)
# Convert tokens to indices using the English vocabulary
src_indices = [en_vocab.get(token, en_vocab['<unk>']) for token in src_tokens]
# Convert indices to tensor and add batch dimension
src_tensor = torch.LongTensor(src_indices).unsqueeze(0)
# Initialize target input with '<sos>' token
trg_input = torch.LongTensor([[fr_vocab['<sos>']]])
# Initialize list to store the generated translation
translation = []
with torch.no_grad():
for i in range(max_len):
# Generate mask for source sentence
src_mask = (src_tensor != en_vocab['<pad>']).unsqueeze(-2)
# Generate mask for target sentence
trg_mask = torch.triu(torch.ones((1, i+1, i+1), device=src_tensor.device)).bool()
# Generate predictions for next token
preds = model(src_tensor, trg_input, src_mask, trg_mask)
# Get predicted token (index)
pred_token = preds.argmax(dim=-1)[:,-1].item()
# Append predicted token to translation list
translation.append(pred_token)
# If predicted token is end-of-sentence token, stop
if pred_token == fr_vocab['<eos>']:
break
# Append predicted token to target input for next iteration
trg_input = torch.cat([trg_input, torch.LongTensor([[pred_token]])], dim=-1)
# Convert indices back to tokens using the French vocabulary
translated_sentence = [fr_index_to_word[token] for token in translation]
return ' '.join(translated_sentence)
for src_sentence in en_data:
translation = translate(model, src_sentence, en_vocab, fr_vocab)
print("Source:", src_sentence)
print("Translation:", translation)
print()