Convolutional Neural Networks
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet pandas scikit-learn numpy matplotlib jupyterlab_myst ipython imageio scikit-image requests
# Convolutional Neural Networks
23. Convolutional Neural Networks#
Convolutional Neural Networks (CNNs) are responsible for the latest major breakthroughs in image recognition in the past few years.
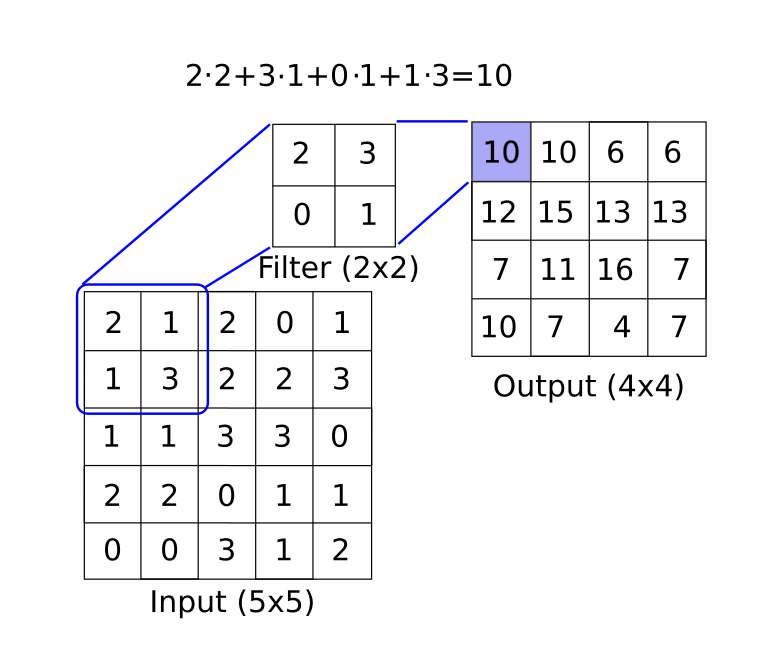
In mathematics, a convolution is a function that is applied over the output of another function. In our case, we will consider applying a matrix multiplication (filter) across an image. See the below diagram for an example of how this may work.
from IPython.display import HTML
display(HTML("""
<p style="text-align: center;">
<iframe src="https://static-1300131294.cos.ap-shanghai.myqcloud.com/html/conv-demo/index.html" width="105%" height="800px;"
style="border:none;" scrolling="auto"></iframe>
A demo of convolution function. <a
href="https://cs231n.github.io/convolutional-networks/"> [source]</a>
</p>
"""))
A demo of convolution function. [source]
CNNs generally follow a structure. The main convolutional setup is (input array) -> (convolutional filter layer) -> (Pooling) -> (Activation layer). The above diagram depicts how a convolutional layer may create one feature. Generally, filters are multidimensional and end up creating many features. It is also common to have a completely separate filter-feature creator of different sizes acting on the same layer. After this convolutional filter, it is common to apply a pooling layer. This pooling may be a max-pooling or an average pooling or another aggregation. One of the key concepts here is that the pooling layer has no parameters while decreasing the layer size. See the below diagram for an example of max-pooling.
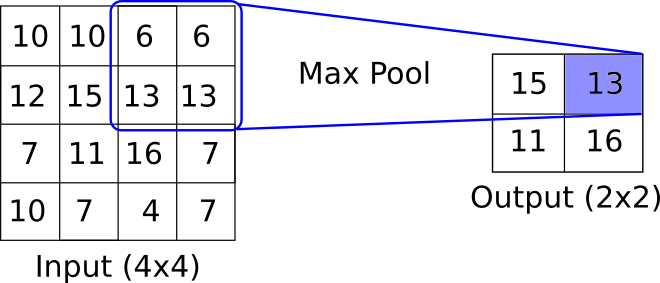
After the max pooling, there is generally an activation layer. One of the more common activation layers is the ReLU (Rectified Linear Unit).
23.1. MNIST handwritten digits#
Here we illustrate how to use a simple CNN with three convolutional units to predict the MNIST handwritten digits.
Note
There is good reason why this dataset is used like the ‘hello world’ of image recognition, it is fairly compact while having a decent amount of training, test, and validation data. It only has one channel (black and white) and only ten possible outputs (0-9).
When the script is done training the model, you should see similar output to the following graphs.
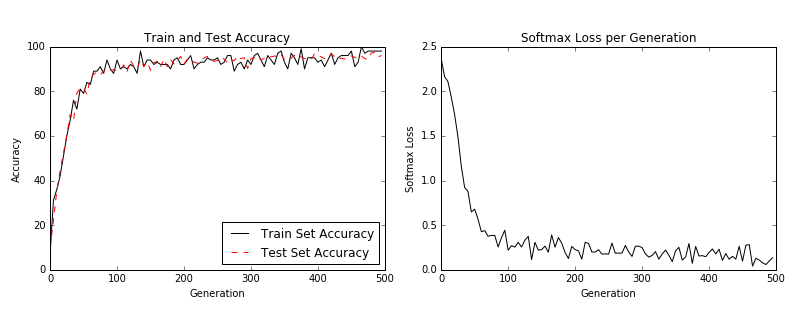
Training and test loss (left) and test batch accuracy (right).

A random set of 6 digits with actual and predicted labels. You can see a prediction failure in the lower right box.
from IPython.display import HTML
display(HTML("""
<p style="text-align: center;">
<iframe src="https://static-1300131294.cos.ap-shanghai.myqcloud.com/html/cnn-vis/cnn.html" width="105%" height="800px;"
style="border:none;" scrolling="auto"></iframe>
A demo of CNN. <a
href="https://adamharley.com/nn_vis/cnn/3d.html"> [source]</a>
</p>
"""))
A demo of CNN. [source]
from IPython.display import HTML
display(HTML("""
<p style="text-align: center;">
<iframe src="https://static-1300131294.cos.ap-shanghai.myqcloud.com/html/cnn-vis-3/index.html" width="105%" height="600px;"
style="border:none;" scrolling="auto"></iframe>
A demo of CNN. <a
href="https://poloclub.github.io/cnn-explainer/"> [source]</a>
</p>
"""))
A demo of CNN. [source]
from IPython.display import HTML
display(HTML("""
<p style="text-align: center;">
<iframe src="https://static-1300131294.cos.ap-shanghai.myqcloud.com/html/cnn-vis-2/index.html" width="105%" height="600px;"
style="border:none;" scrolling="auto"></iframe>
A demo of CNN. <a
href="https://poloclub.github.io/cnn-explainer/"> [source]</a>
</p>
"""))
A demo of CNN. [source]
23.2. Code#
23.2.1. Load dataset and data preprocessing#
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
23.2.2. Build model#
warnings.filterwarnings("ignore")
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
23.2.3. Compile model#
warnings.filterwarnings("ignore")
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
23.2.4. Train model#
warnings.filterwarnings("ignore")
history = model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
Epoch 1/5
1875/1875 [==============================] - 16s 9ms/step - loss: 0.0866 - accuracy: 0.9734 - val_loss: 0.0454 - val_accuracy: 0.9839
Epoch 2/5
1875/1875 [==============================] - 16s 9ms/step - loss: 0.0430 - accuracy: 0.9865 - val_loss: 0.0362 - val_accuracy: 0.9872
Epoch 3/5
1875/1875 [==============================] - 16s 9ms/step - loss: 0.0298 - accuracy: 0.9904 - val_loss: 0.0351 - val_accuracy: 0.9878
Epoch 4/5
1875/1875 [==============================] - 16s 9ms/step - loss: 0.0228 - accuracy: 0.9926 - val_loss: 0.0283 - val_accuracy: 0.9902
Epoch 5/5
1875/1875 [==============================] - 17s 9ms/step - loss: 0.0164 - accuracy: 0.9946 - val_loss: 0.0291 - val_accuracy: 0.9912
23.2.5. Test model#
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('Test accuracy:', test_acc)
313/313 - 0s - loss: 0.0330 - accuracy: 0.9899 - 419ms/epoch - 1ms/step
Test accuracy: 0.9898999929428101
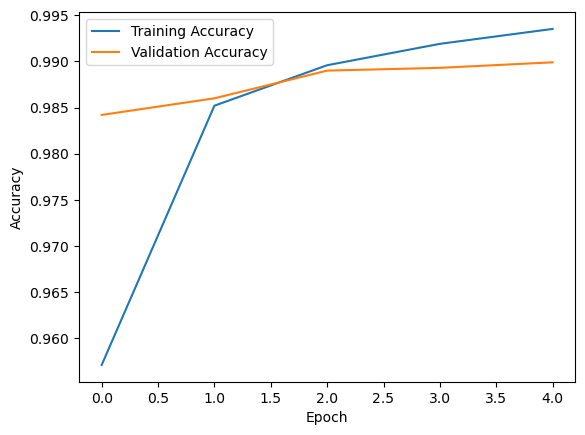
23.2.6. Visualizing the training process#
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
23.2.7. Load data#
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
23.2.8. Normalize pixel values to the range [0, 1]#
train_images = train_images / 255.0
test_images = test_images / 255.0
23.2.9. Convert images to 4D tensors (batch_size, height, width, channels)#
train_images = np.expand_dims(train_images, axis=-1)
test_images = np.expand_dims(test_images, axis=-1)
23.2.10. Set model parameters#
batch_size = 100
learning_rate = 0.005
evaluation_size = 500
image_width = train_images.shape[1]
image_height = train_images.shape[2]
target_size = np.max(train_labels) + 1
num_channels = 1 # greyscale = 1 channel
generations = 500
eval_every = 5
conv1_features = 25
conv2_features = 50
max_pool_size1 = 2 # NxN window for 1st max pool layer
max_pool_size2 = 2 # NxN window for 2nd max pool layer
fully_connected_size1 = 100
23.2.11. Define the model#
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(conv1_features, (4, 4), activation='relu', input_shape=(image_width, image_height, num_channels)),
tf.keras.layers.MaxPooling2D((max_pool_size1, max_pool_size1)),
tf.keras.layers.Conv2D(conv2_features, (4, 4), activation='relu'),
tf.keras.layers.MaxPooling2D((max_pool_size2, max_pool_size2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(fully_connected_size1, activation='relu'),
tf.keras.layers.Dense(target_size)
])
23.2.12. Compile the model#
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
23.2.13. Train the model#
train_loss = []
train_acc = []
test_acc = []
for i in range(generations):
rand_index = np.random.choice(len(train_images), size=batch_size)
rand_x = train_images[rand_index]
rand_y = train_labels[rand_index]
history = model.train_on_batch(rand_x, rand_y)
temp_train_loss, temp_train_acc = history[0], history[1]
if (i+1) % eval_every == 0:
eval_index = np.random.choice(len(test_images), size=evaluation_size)
eval_x = test_images[eval_index]
eval_y = test_labels[eval_index]
test_loss, temp_test_acc = model.evaluate(eval_x, eval_y, verbose=0)
# Record and print results
train_loss.append(temp_train_loss)
train_acc.append(temp_train_acc)
test_acc.append(temp_test_acc)
acc_and_loss = [(i+1), temp_train_loss, temp_train_acc * 100, temp_test_acc * 100]
acc_and_loss = [np.round(x, 2) for x in acc_and_loss]
print('Generation # {}. Train Loss: {:.2f}. Train Acc (Test Acc): {:.2f}% ({:.2f}%)'.format(*acc_and_loss))
Generation # 5. Train Loss: 2.29. Train Acc (Test Acc): 11.00% (10.00%)
Generation # 10. Train Loss: 2.30. Train Acc (Test Acc): 8.00% (14.20%)
Generation # 15. Train Loss: 2.25. Train Acc (Test Acc): 30.00% (31.80%)
Generation # 20. Train Loss: 2.25. Train Acc (Test Acc): 33.00% (30.00%)
Generation # 25. Train Loss: 2.22. Train Acc (Test Acc): 39.00% (38.20%)
Generation # 30. Train Loss: 2.21. Train Acc (Test Acc): 37.00% (36.40%)
Generation # 35. Train Loss: 2.15. Train Acc (Test Acc): 43.00% (48.60%)
Generation # 40. Train Loss: 2.10. Train Acc (Test Acc): 50.00% (51.20%)
Generation # 45. Train Loss: 2.05. Train Acc (Test Acc): 44.00% (51.40%)
Generation # 50. Train Loss: 1.97. Train Acc (Test Acc): 52.00% (60.60%)
Generation # 55. Train Loss: 1.84. Train Acc (Test Acc): 63.00% (59.20%)
Generation # 60. Train Loss: 1.55. Train Acc (Test Acc): 69.00% (66.20%)
Generation # 65. Train Loss: 1.40. Train Acc (Test Acc): 62.00% (62.40%)
Generation # 70. Train Loss: 1.13. Train Acc (Test Acc): 75.00% (73.40%)
Generation # 75. Train Loss: 0.95. Train Acc (Test Acc): 75.00% (74.40%)
Generation # 80. Train Loss: 0.67. Train Acc (Test Acc): 81.00% (80.80%)
Generation # 85. Train Loss: 0.74. Train Acc (Test Acc): 77.00% (80.40%)
Generation # 90. Train Loss: 0.69. Train Acc (Test Acc): 84.00% (79.80%)
Generation # 95. Train Loss: 0.57. Train Acc (Test Acc): 83.00% (83.40%)
Generation # 100. Train Loss: 0.50. Train Acc (Test Acc): 86.00% (83.20%)
Generation # 105. Train Loss: 0.44. Train Acc (Test Acc): 83.00% (88.80%)
Generation # 110. Train Loss: 0.45. Train Acc (Test Acc): 84.00% (82.00%)
Generation # 115. Train Loss: 0.47. Train Acc (Test Acc): 86.00% (86.60%)
Generation # 120. Train Loss: 0.34. Train Acc (Test Acc): 92.00% (89.60%)
Generation # 125. Train Loss: 0.39. Train Acc (Test Acc): 84.00% (85.40%)
Generation # 130. Train Loss: 0.41. Train Acc (Test Acc): 85.00% (87.60%)
Generation # 135. Train Loss: 0.42. Train Acc (Test Acc): 87.00% (89.60%)
Generation # 140. Train Loss: 0.30. Train Acc (Test Acc): 90.00% (90.00%)
Generation # 145. Train Loss: 0.43. Train Acc (Test Acc): 83.00% (90.40%)
Generation # 150. Train Loss: 0.63. Train Acc (Test Acc): 86.00% (90.40%)
Generation # 155. Train Loss: 0.34. Train Acc (Test Acc): 94.00% (90.80%)
Generation # 160. Train Loss: 0.40. Train Acc (Test Acc): 89.00% (92.80%)
Generation # 165. Train Loss: 0.35. Train Acc (Test Acc): 89.00% (93.80%)
Generation # 170. Train Loss: 0.31. Train Acc (Test Acc): 89.00% (89.80%)
Generation # 175. Train Loss: 0.32. Train Acc (Test Acc): 89.00% (92.60%)
Generation # 180. Train Loss: 0.20. Train Acc (Test Acc): 97.00% (89.40%)
Generation # 185. Train Loss: 0.30. Train Acc (Test Acc): 92.00% (92.40%)
Generation # 190. Train Loss: 0.28. Train Acc (Test Acc): 92.00% (91.80%)
Generation # 195. Train Loss: 0.28. Train Acc (Test Acc): 89.00% (91.80%)
Generation # 200. Train Loss: 0.25. Train Acc (Test Acc): 93.00% (91.40%)
Generation # 205. Train Loss: 0.17. Train Acc (Test Acc): 96.00% (91.60%)
Generation # 210. Train Loss: 0.26. Train Acc (Test Acc): 91.00% (93.60%)
Generation # 215. Train Loss: 0.29. Train Acc (Test Acc): 89.00% (91.60%)
Generation # 220. Train Loss: 0.25. Train Acc (Test Acc): 92.00% (91.60%)
Generation # 225. Train Loss: 0.28. Train Acc (Test Acc): 88.00% (92.00%)
Generation # 230. Train Loss: 0.21. Train Acc (Test Acc): 91.00% (92.00%)
Generation # 235. Train Loss: 0.33. Train Acc (Test Acc): 87.00% (91.20%)
Generation # 240. Train Loss: 0.23. Train Acc (Test Acc): 95.00% (90.80%)
Generation # 245. Train Loss: 0.21. Train Acc (Test Acc): 91.00% (92.20%)
Generation # 250. Train Loss: 0.20. Train Acc (Test Acc): 94.00% (92.40%)
Generation # 255. Train Loss: 0.27. Train Acc (Test Acc): 95.00% (91.80%)
Generation # 260. Train Loss: 0.29. Train Acc (Test Acc): 94.00% (91.80%)
Generation # 265. Train Loss: 0.25. Train Acc (Test Acc): 93.00% (91.80%)
Generation # 270. Train Loss: 0.38. Train Acc (Test Acc): 90.00% (93.40%)
Generation # 275. Train Loss: 0.29. Train Acc (Test Acc): 92.00% (94.60%)
Generation # 280. Train Loss: 0.31. Train Acc (Test Acc): 93.00% (95.00%)
Generation # 285. Train Loss: 0.36. Train Acc (Test Acc): 90.00% (94.80%)
Generation # 290. Train Loss: 0.15. Train Acc (Test Acc): 94.00% (93.00%)
Generation # 295. Train Loss: 0.18. Train Acc (Test Acc): 95.00% (95.20%)
Generation # 300. Train Loss: 0.32. Train Acc (Test Acc): 87.00% (93.00%)
Generation # 305. Train Loss: 0.16. Train Acc (Test Acc): 94.00% (92.80%)
Generation # 310. Train Loss: 0.09. Train Acc (Test Acc): 98.00% (94.60%)
Generation # 315. Train Loss: 0.15. Train Acc (Test Acc): 95.00% (96.20%)
Generation # 320. Train Loss: 0.16. Train Acc (Test Acc): 94.00% (94.40%)
Generation # 325. Train Loss: 0.32. Train Acc (Test Acc): 92.00% (94.00%)
Generation # 330. Train Loss: 0.24. Train Acc (Test Acc): 90.00% (95.80%)
Generation # 335. Train Loss: 0.16. Train Acc (Test Acc): 94.00% (94.60%)
Generation # 340. Train Loss: 0.17. Train Acc (Test Acc): 96.00% (95.60%)
Generation # 345. Train Loss: 0.10. Train Acc (Test Acc): 99.00% (92.40%)
Generation # 350. Train Loss: 0.13. Train Acc (Test Acc): 95.00% (95.00%)
Generation # 355. Train Loss: 0.14. Train Acc (Test Acc): 97.00% (95.80%)
Generation # 360. Train Loss: 0.24. Train Acc (Test Acc): 93.00% (95.20%)
Generation # 365. Train Loss: 0.30. Train Acc (Test Acc): 92.00% (93.80%)
Generation # 370. Train Loss: 0.13. Train Acc (Test Acc): 96.00% (94.20%)
Generation # 375. Train Loss: 0.19. Train Acc (Test Acc): 94.00% (95.20%)
Generation # 380. Train Loss: 0.20. Train Acc (Test Acc): 94.00% (95.20%)
Generation # 385. Train Loss: 0.33. Train Acc (Test Acc): 93.00% (94.00%)
Generation # 390. Train Loss: 0.10. Train Acc (Test Acc): 97.00% (93.00%)
Generation # 395. Train Loss: 0.25. Train Acc (Test Acc): 93.00% (93.20%)
Generation # 400. Train Loss: 0.17. Train Acc (Test Acc): 95.00% (94.40%)
Generation # 405. Train Loss: 0.25. Train Acc (Test Acc): 90.00% (94.80%)
Generation # 410. Train Loss: 0.13. Train Acc (Test Acc): 97.00% (95.00%)
Generation # 415. Train Loss: 0.20. Train Acc (Test Acc): 94.00% (92.40%)
Generation # 420. Train Loss: 0.16. Train Acc (Test Acc): 95.00% (95.20%)
Generation # 425. Train Loss: 0.27. Train Acc (Test Acc): 92.00% (94.80%)
Generation # 430. Train Loss: 0.07. Train Acc (Test Acc): 99.00% (96.60%)
Generation # 435. Train Loss: 0.20. Train Acc (Test Acc): 94.00% (96.60%)
Generation # 440. Train Loss: 0.11. Train Acc (Test Acc): 97.00% (96.60%)
Generation # 445. Train Loss: 0.13. Train Acc (Test Acc): 94.00% (95.80%)
Generation # 450. Train Loss: 0.06. Train Acc (Test Acc): 99.00% (96.40%)
Generation # 455. Train Loss: 0.09. Train Acc (Test Acc): 99.00% (95.60%)
Generation # 460. Train Loss: 0.13. Train Acc (Test Acc): 96.00% (95.80%)
Generation # 465. Train Loss: 0.13. Train Acc (Test Acc): 96.00% (95.60%)
Generation # 470. Train Loss: 0.14. Train Acc (Test Acc): 96.00% (96.20%)
Generation # 475. Train Loss: 0.15. Train Acc (Test Acc): 97.00% (96.80%)
Generation # 480. Train Loss: 0.19. Train Acc (Test Acc): 95.00% (97.00%)
Generation # 485. Train Loss: 0.22. Train Acc (Test Acc): 91.00% (95.80%)
Generation # 490. Train Loss: 0.11. Train Acc (Test Acc): 97.00% (96.20%)
Generation # 495. Train Loss: 0.20. Train Acc (Test Acc): 94.00% (96.60%)
Generation # 500. Train Loss: 0.10. Train Acc (Test Acc): 98.00% (95.60%)
23.2.14. Plot figures#
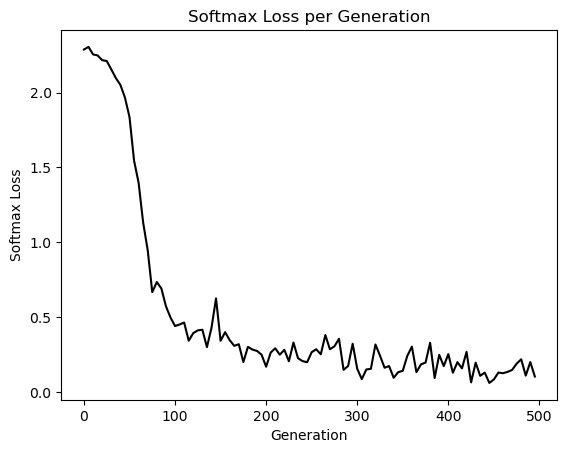
# Plot loss over time
plt.plot(range(0, generations, eval_every), train_loss, 'k-')
plt.title('Softmax Loss per Generation')
plt.xlabel('Generation')
plt.ylabel('Softmax Loss')
plt.show()
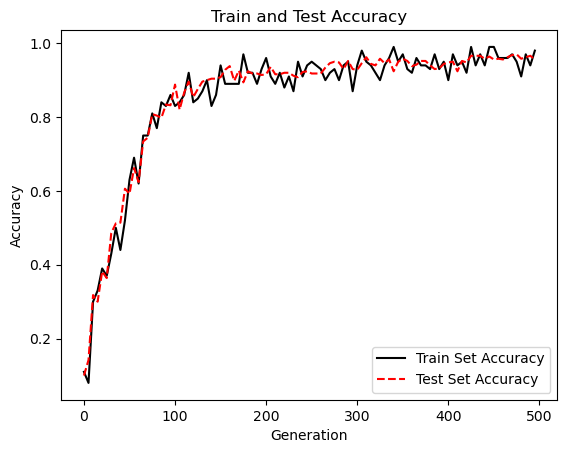
# Plot train and test accuracy
plt.plot(range(0, generations, eval_every), train_acc, 'k-', label='Train Set Accuracy')
plt.plot(range(0, generations, eval_every), test_acc, 'r--', label='Test Set Accuracy')
plt.title('Train and Test Accuracy')
plt.xlabel('Generation')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
# Plot some samples
# Plot the 6 of the last batch results:
predictions = model.predict(train_images[:6])
predictions = np.argmax(predictions, axis=1)
images = np.squeeze(train_images[:6])
Nrows = 2
Ncols = 3
for i in range(6):
plt.subplot(Nrows, Ncols, i+1)
plt.imshow(np.reshape(images[i], [28, 28]), cmap='Greys_r')
plt.title('Pred: ' + str(predictions[i]), fontsize=10)
frame = plt.gca()
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
plt.show()
1/1 [==============================] - 0s 74ms/step

23.3. CIFAR-10#
Here we will build a convolutional neural network to predict the CIFAR-10 data.
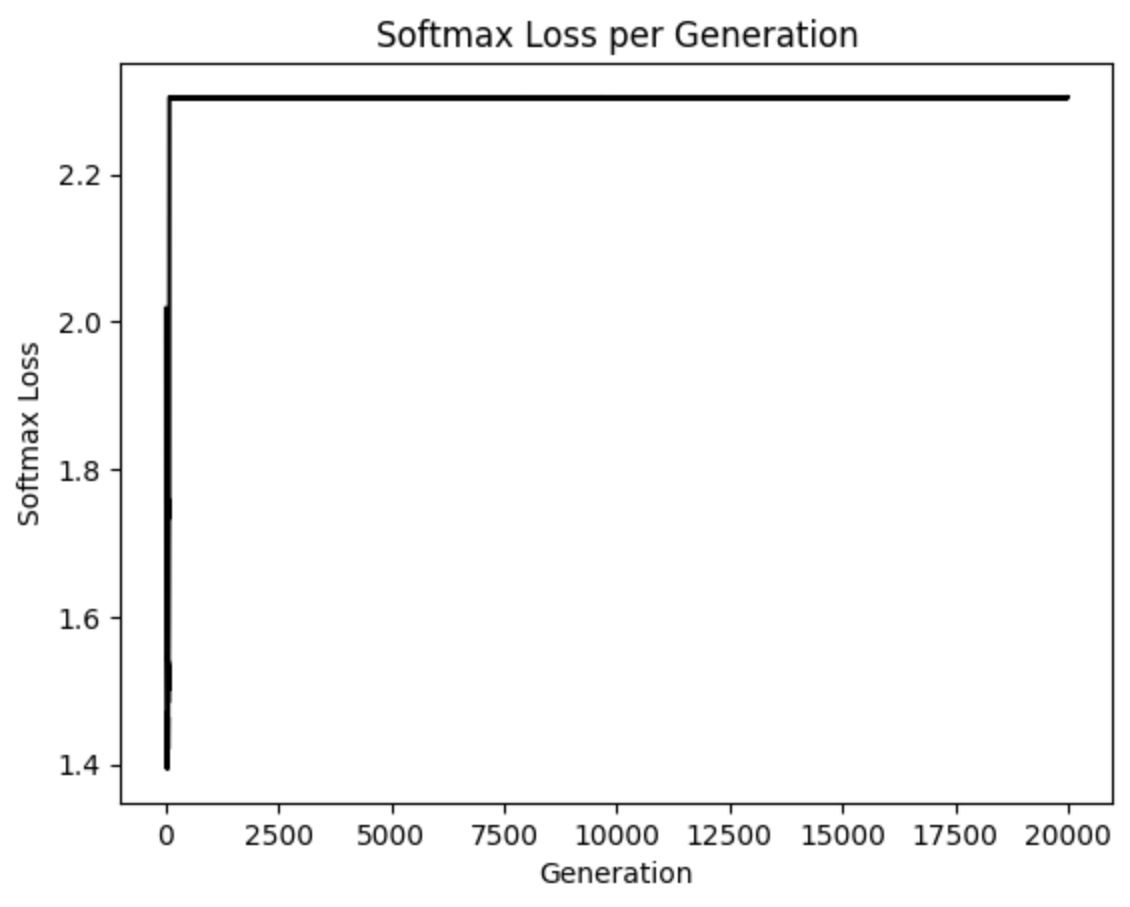
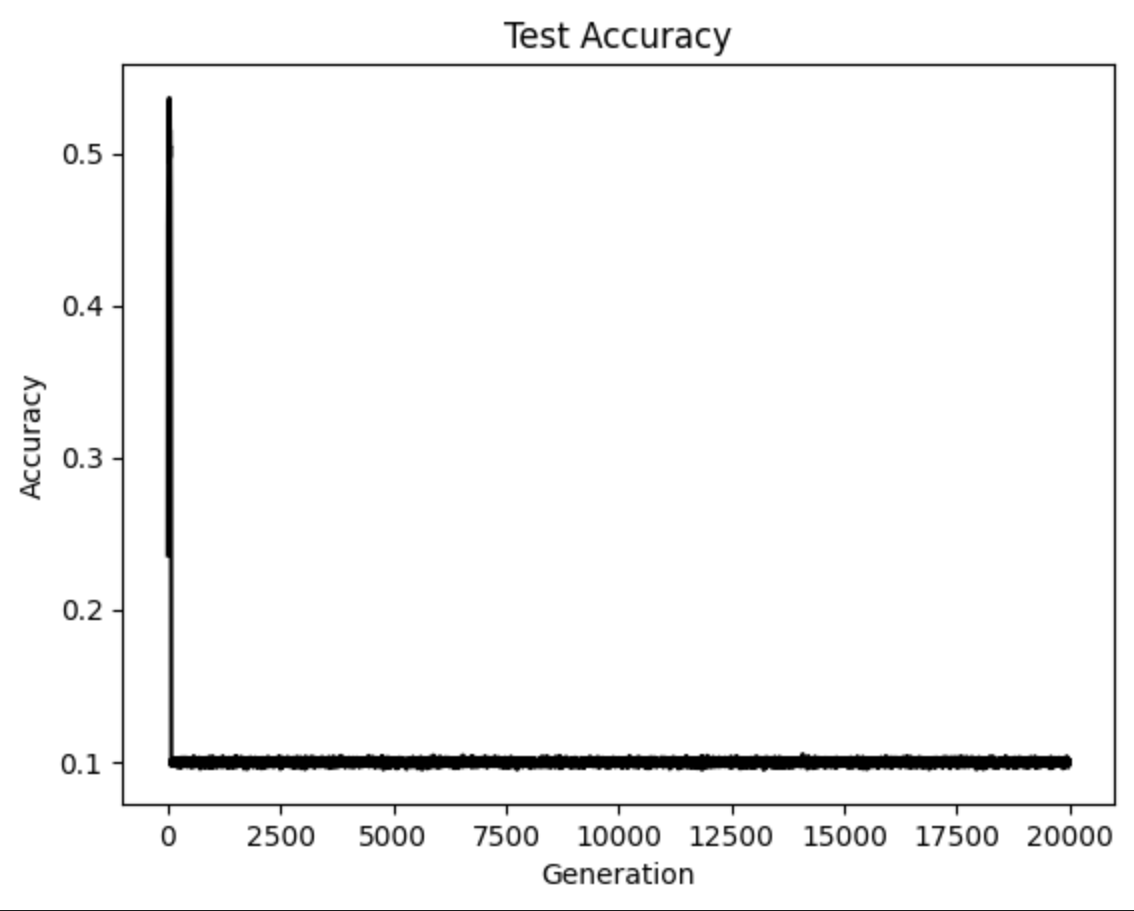
The script provided will download and unzip the CIFAR-10 data. Then it will start training a CNN from scratch. You should see similar output at the end of the following two graphs.
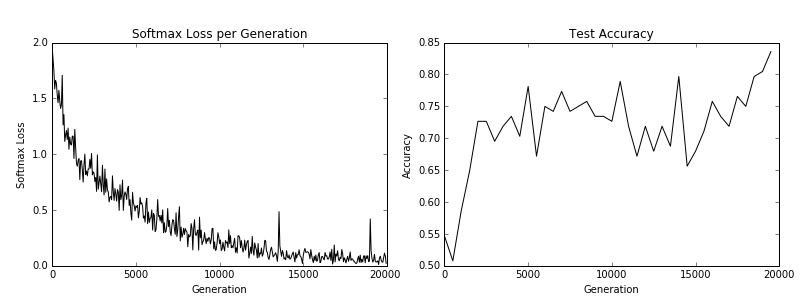
Here we see the training loss (left) and the test batch accuracy (right).
23.4. Code#
23.4.1. Set model parameters#
import os
import tensorflow as tf
import matplotlib.pyplot as plt
import urllib.request
batch_size = 128
data_dir = 'temp'
output_every = 50
generations = 20000
eval_every = 500
image_height = 32
image_width = 32
crop_height = 24
crop_width = 24
num_channels = 3
num_targets = 10
extract_folder = 'cifar-10-batches-bin'
23.4.2. Load data#
data_dir = 'temp'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
cifar10_url = 'http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz'
# Check if file exists, otherwise download it
data_file = os.path.join(data_dir, 'cifar-10-binary.tar.gz')
if os.path.isfile(data_file):
pass
else:
# Download file
def progress(block_num, block_size, total_size):
progress_info = [cifar10_url, float(block_num * block_size) / float(total_size) * 100.0]
print('\r Downloading {} - {:.2f}%'.format(*progress_info), end="")
filepath, _ = urllib.request.urlretrieve(cifar10_url, data_file, progress)
# Extract file
tarfile.open(filepath, 'r:gz').extractall(data_dir)
23.4.3. Load CIFAR-10 dataset#
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.cifar10.load_data()
# Preprocess the data
train_images = train_images / 255.0
test_images = test_images / 255.0
# Crop images
train_images = tf.image.crop_to_bounding_box(train_images, 4, 4, 24, 24)
test_images = tf.image.crop_to_bounding_box(test_images, 4, 4, 24, 24)
23.4.4. Convert labels to integers#
train_labels = train_labels.flatten()
test_labels = test_labels.flatten()
23.4.5. Define the model architecture#
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(64, (5, 5), activation='relu', input_shape=(crop_height, crop_width, num_channels)),
tf.keras.layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2)),
tf.keras.layers.Conv2D(64, (5, 5), activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(384, activation='relu'),
tf.keras.layers.Dense(192, activation='relu'),
tf.keras.layers.Dense(num_targets)
])
23.4.6. Define loss function#
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# Create accuracy metric
accuracy_metric = tf.keras.metrics.SparseCategoricalAccuracy()
# Create optimizer
optimizer = tf.keras.optimizers.SGD(learning_rate=0.1, momentum=0.9)
# Compile the model
model.compile(optimizer=optimizer, loss=loss_fn, metrics=[accuracy_metric])
# Train the model
history = model.fit(train_images, train_labels, batch_size=batch_size, epochs=generations,
validation_data=(test_images, test_labels), verbose=1)
# Evaluate the model
test_loss, test_accuracy = model.evaluate(test_images, test_labels, verbose=0)
23.4.7. Print loss and accuracy#
print('Test Loss:', test_loss)
print('Test Accuracy:', test_accuracy)
# Plot loss over time
plt.plot(history.history['loss'], 'k-')
plt.title('Softmax Loss per Generation')
plt.xlabel('Generation')
plt.ylabel('Softmax Loss')
plt.show()
# Plot accuracy over time
plt.plot(history.history['sparse_categorical_accuracy'], 'k-')
plt.title('Test Accuracy')
plt.xlabel('Generation')
plt.ylabel('Accuracy')
plt.show()
23.5. How to fine-tune current CNN architectures?#
The purpose of the script provided in this section is to download the CIFAR-10 data and sort it out in the proper folder structure for running it through the TensorFlow fine-tuning tutorial. The script should create the following folder structure.
23.5.1. Code#
In this script, we download the CIFAR-10 images and transform/save them in the Inception Retraining Format The end purpose of the files is for re-training the Google Inception tensorflow model to work on the CIFAR-10.
import os
import tarfile
import pickle as cPickle
import numpy as np
import urllib.request
import imageio
from tensorflow.python.framework import ops
ops.reset_default_graph()
cifar_link = 'https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz'
data_dir = 'temp'
if not os.path.isdir(data_dir):
os.makedirs(data_dir)
23.5.2. Download tar file#
target_file = os.path.join(data_dir, 'cifar-10-python.tar.gz')
if not os.path.isfile(target_file):
print('CIFAR-10 file not found. Downloading CIFAR data (Size = 163MB)')
print('This may take a few minutes, please wait.')
filename, headers = urllib.request.urlretrieve(cifar_link, target_file)
23.5.3. Extract into memory#
tar = tarfile.open(target_file)
tar.extractall(path=data_dir)
tar.close()
objects = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# Create train image folders
train_folder = 'train_dir'
if not os.path.isdir(os.path.join(data_dir, train_folder)):
for i in range(10):
folder = os.path.join(data_dir, train_folder, objects[i])
os.makedirs(folder)
23.5.4. Create test image folders#
test_folder = 'validation_dir'
if not os.path.isdir(os.path.join(data_dir, test_folder)):
for i in range(10):
folder = os.path.join(data_dir, test_folder, objects[i])
os.makedirs(folder)
23.5.5. Extract images accordingly#
data_location = os.path.join(data_dir, 'cifar-10-batches-py')
train_names = ['data_batch_' + str(x) for x in range(1,6)]
test_names = ['test_batch']
23.5.6. Define functions#
def load_batch_from_file(file):
file_conn = open(file, 'rb')
image_dictionary = cPickle.load(file_conn, encoding='latin1')
file_conn.close()
return image_dictionary
def save_images_from_dict(image_dict, folder='data_dir'):
# image_dict.keys() = 'labels', 'filenames', 'data', 'batch_label'
for ix, label in enumerate(image_dict['labels']):
folder_path = os.path.join(data_dir, folder, objects[label])
filename = image_dict['filenames'][ix]
# Transform image data
image_array = image_dict['data'][ix]
image_array.resize([3, 32, 32])
# Save image using imageio
output_location = os.path.join(folder_path, filename)
# Ensure the pixel values are in the range [0, 255]
image_array = np.clip(image_array, 0, 255).astype(np.uint8)
imageio.imwrite(output_location, image_array.transpose(1, 2, 0))
23.5.7. Sort train images and sort test images#
for file in train_names:
print('Saving images from file: {}'.format(file))
file_location = os.path.join(data_dir, 'cifar-10-batches-py', file)
image_dict = load_batch_from_file(file_location)
save_images_from_dict(image_dict, folder=train_folder)
for file in test_names:
print('Saving images from file: {}'.format(file))
file_location = os.path.join(data_dir, 'cifar-10-batches-py', file)
image_dict = load_batch_from_file(file_location)
save_images_from_dict(image_dict, folder=test_folder)
23.5.8. Create labels file#
cifar_labels_file = os.path.join(data_dir,'cifar10_labels.txt')
print('Writing labels file, {}'.format(cifar_labels_file))
with open(cifar_labels_file, 'w') as labels_file:
for item in objects:
labels_file.write("{}\n".format(item))
23.6. Your turn! 🚀#
You can practice your cnn skills by following the assignment how to choose cnn architecture mnist
23.7. Self study#
You can refer to those YouTube videos for further study:
Convolutional Neural Networks (CNNs) explained, by deeplizard
Convolutional Neural Networks Explained (CNN Visualized), by Futurology
23.7.1. Research trend#
State of the Art Convolutional Neural Networks (CNNs) Explained | Deep Learning in 2020:
23.8. Acknowledgments#
Thanks to Nick for creating the open-source course tensorflow_cookbook. It inspires the majority of the content in this chapter.