Basic classification: Classify images of clothing
Contents
42.125. Basic classification: Classify images of clothing#
42.125.1. Load model#
The following code has nothing to do with machine learning and can be skipped.
import os
import requests
classification_model_url = "https://static-1300131294.cos.ap-shanghai.myqcloud.com/data/deep-learning/overview/classification.h5"
notebook_path = os.getcwd()
tmp_folder_path = os.path.join(notebook_path, "tmp")
if not os.path.exists(tmp_folder_path):
os.makedirs(tmp_folder_path)
file_path = os.path.join(tmp_folder_path,"overview")
if not os.path.exists(file_path):
os.makedirs(file_path)
zip_store_path = os.path.join(file_path, "zip-store")
if not os.path.exists(zip_store_path):
os.makedirs(zip_store_path)
classification_model_response = requests.get(classification_model_url)
classification_model_name = os.path.basename(classification_model_url)
classification_model_save_path = os.path.join(file_path, classification_model_name)
with open(classification_model_save_path, "wb") as file:
file.write(classification_model_response.content)
42.125.2. Overview: Deep learning, machine learning, and AI#
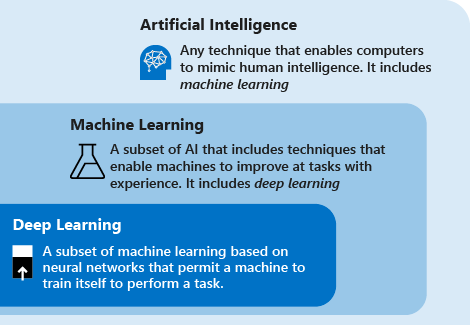
Consider the following definitions to understand deep learning vs. machine learning vs. AI:
Deep learning is a subset of machine learning that’s based on artificial neural networks. The learning process is deep because the structure of artificial neural networks consists of multiple input, output, and hidden layers. Each layer contains units that transform the input data into information that the next layer can use for a certain predictive task. Thanks to this structure, a machine can learn through its own data processing.
Machine learning is a subset of artificial intelligence that uses techniques (such as deep learning) that enable machines to use experience to improve at tasks. The learning process is based on the following steps:
Feed data into an algorithm. (In this step you can provide additional information to the model, for example, by performing feature extraction.) Use this data to train a model.
Test and deploy the model.
Consume the deployed model to do an automated predictive task. (In other words, call and use the deployed model to receive the predictions returned by the model.)
Artificial intelligence (AI) is a technique that enables computers to mimic human intelligence. It includes machine learning.
Generative AI is a subset of artificial intelligence that uses techniques (such as deep learning) to generate new content. For example, you can use generative AI to create images, text, or audio. These models leverage massive pre-trained knowledge to generate this content.
By using machine learning and deep learning techniques, you can build computer systems and applications that do tasks that are commonly associated with human intelligence. These tasks include image recognition, speech recognition, and language translation.
42.125.3. Overview of this guide#
This guide provide a simple sample of deep learning. It will help you understand the model framework for deep learning.
This guide trains a neural network model to classify images of clothing, like sneakers and shirts. It’s okay if you don’t understand all the details; this is a fast-paced overview of a complete TensorFlow program with the details explained as you go.
This guide uses tf.keras, a high-level API to build and train models in TensorFlow.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
42.125.4. Import the Fashion MNIST dataset#
This guide uses the Fashion MNIST dataset which contains 70,000 grayscale images in 10 categories. The images show individual articles of clothing at low resolution (28 by 28 pixels), as seen here:
|
|
|
Figure 1. Fashion-MNIST samples (by Zalando, MIT License). |
Fashion MNIST is intended as a drop-in replacement for the classic MNIST dataset—often used as the “Hello, World” of machine learning programs for computer vision. The MNIST dataset contains images of handwritten digits (0, 1, 2, etc.) in a format identical to that of the articles of clothing you’ll use here.
This guide uses Fashion MNIST for variety, and because it’s a slightly more challenging problem than regular MNIST. Both datasets are relatively small and are used to verify that an algorithm works as expected. They’re good starting points to test and debug code.
Here, 60,000 images are used to train the network and 10,000 images to evaluate how accurately the network learned to classify images. You can access the Fashion MNIST directly from TensorFlow. Import and load the Fashion MNIST data directly from TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Loading the dataset returns four NumPy arrays:
The
train_imagesandtrain_labelsarrays are the training set—the data the model uses to learn.The model is tested against the test set, the
test_images, andtest_labelsarrays.
The images are 28x28 NumPy arrays, with pixel values ranging from 0 to 255. The labels are an array of integers, ranging from 0 to 9. These correspond to the class of clothing the image represents:
| Label | Class |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
Each image is mapped to a single label. Since the class names are not included with the dataset, store them here to use later when plotting the images:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
42.125.5. Explore the data#
Let’s explore the format of the dataset before training the model. The following shows there are 60,000 images in the training set, with each image represented as 28 x 28 pixels:
train_images.shape
Likewise, there are 60,000 labels in the training set:
len(train_labels)
Each label is an integer between 0 and 9:
train_labels
There are 10,000 images in the test set. Again, each image is represented as 28 x 28 pixels:
test_images.shape
And the test set contains 10,000 images labels:
len(test_labels)
42.125.6. Preprocess the data#
The data must be preprocessed before training the network. If you inspect the first image in the training set, you will see that the pixel values fall in the range of 0 to 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
Scale these values to a range of 0 to 1 before feeding them to the neural network model. To do so, divide the values by 255. It’s important that the training set and the testing set be preprocessed in the same way:
train_images = train_images / 255.0
test_images = test_images / 255.0
To verify that the data is in the correct format and that you’re ready to build and train the network, let’s display the first 25 images from the training set and display the class name below each image.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
42.125.7. Build the model#
Building the neural network requires configuring the layers of the model, then compiling the model.
42.125.7.1. Set up the layers#
The basic building block of a neural network is the layer. Layers extract representations from the data fed into them. Hopefully, these representations are meaningful for the problem at hand.
Most of deep learning consists of chaining together simple layers. Most layers, such as tf.keras.layers.Dense, have parameters that are learned during training.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
The first layer in this network, tf.keras.layers.Flatten, transforms the format of the images from a two-dimensional array (of 28 by 28 pixels) to a one-dimensional array (of 28 * 28 = 784 pixels). Think of this layer as unstacking rows of pixels in the image and lining them up. This layer has no parameters to learn; it only reformats the data.
After the pixels are flattened, the network consists of a sequence of two tf.keras.layers.Dense layers. These are densely connected, or fully connected, neural layers. The first Dense layer has 128 nodes (or neurons). The second (and last) layer returns a logits array with length of 10. Each node contains a score that indicates the current image belongs to one of the 10 classes.
42.125.7.2. Compile the model#
Before the model is ready for training, it needs a few more settings. These are added during the model’s compile step:
Loss function —This measures how accurate the model is during training. You want to minimize this function to “steer” the model in the right direction.
Optimizer —This is how the model is updated based on the data it sees and its loss function.
Metrics —Used to monitor the training and testing steps. The following example uses accuracy, the fraction of the images that are correctly classified.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
42.125.8. Train the model#
Training the neural network model requires the following steps:
Feed the training data to the model. In this example, the training data is in the
train_imagesandtrain_labelsarrays.The model learns to associate images and labels.
You ask the model to make predictions about a test set—in this example, the
test_imagesarray.Verify that the predictions match the labels from the
test_labelsarray.
42.125.8.1. Feed the model#
To start training, call the model.fit method—so called because it “fits” the model to the training data:
# model.fit(train_images, train_labels, epochs=10)
model = tf.keras.models.load_model('./tmp/overview/classification.h5')
model.save('classification.h5')
As the model trains, the loss and accuracy metrics are displayed. This model reaches an accuracy of about 0.91 (or 91%) on the training data.
42.125.8.2. Evaluate accuracy#
Next, compare how the model performs on the test dataset:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
It turns out that the accuracy on the test dataset is a little less than the accuracy on the training dataset. This gap between training accuracy and test accuracy represents overfitting. Overfitting happens when a machine learning model performs worse on new, previously unseen inputs than it does on the training data. An overfitted model “memorizes” the noise and details in the training dataset to a point where it negatively impacts the performance of the model on the new data. For more information, see the following:
42.125.8.3. Make predictions#
With the model trained, you can use it to make predictions about some images. Attach a softmax layer to convert the model’s linear outputs—logits—to probabilities, which should be easier to interpret.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
Here, the model has predicted the label for each image in the testing set. Let’s take a look at the first prediction:
predictions[0]
A prediction is an array of 10 numbers. They represent the model’s “confidence” that the image corresponds to each of the 10 different articles of clothing. You can see which label has the highest confidence value:
np.argmax(predictions[0])
So, the model is most confident that this image is an ankle boot, or class_names[9]. Examining the test label shows that this classification is correct:
test_labels[0]
Graph this to look at the full set of 10 class predictions.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
42.125.8.4. Verify predictions#
With the model trained, you can use it to make predictions about some images.
Let’s look at the 0th image, predictions, and prediction array. Correct prediction labels are blue and incorrect prediction labels are red. The number gives the percentage (out of 100) for the predicted label.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
Let’s plot several images with their predictions. Note that the model can be wrong even when very confident.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()
42.125.9. Use the trained model#
Finally, use the trained model to make a prediction about a single image.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
tf.keras models are optimized to make predictions on a batch, or collection, of examples at once. Accordingly, even though you’re using a single image, you need to add it to a list:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
Now predict the correct label for this image:
predictions_single = probability_model.predict(img)
print(predictions_single)
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
tf.keras.Model.predict returns a list of lists—one list for each image in the batch of data. Grab the predictions for our (only) image in the batch:
np.argmax(predictions_single[0])
And the model predicts a label as expected.
42.125.10. Acknowledgments#
Thanks to Tensorflow docs for creating the Tensorflow notebook Basic classification: Classify images of clothing. It inspires the majority of the content in this chapter.
Thanks to Microsoft for providing overview of deep learning, machine learning, and AI.