Recurrent Neural Networks
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet pandas scikit-learn numpy matplotlib jupyterlab_myst ipython tensorflow
WARNING: Ignoring invalid distribution -fds-nightly (c:\users\16111\.conda\envs\open-machine-learning-jupyter-book\lib\site-packages)
WARNING: Ignoring invalid distribution -fds-nightly (c:\users\16111\.conda\envs\open-machine-learning-jupyter-book\lib\site-packages)
24. Recurrent Neural Networks#
The nervous system contains many circular paths, whose activity so regenerates the excitation of any participant neuron that reference to time past becomes indefinite, although it still implies that afferent activity has realized one of a certain class of configurations over time. Precise specification of these implications by means of recursive functions, and determination of those that can be embodied in the activity of nervous nets, completes the theory.
– Warren McCulloch and Walter Pitts, 1943
A recurrent neural network (RNN) is a type of artificial neural network that uses sequential data or time series data and it is mainly used for Natural Language Processing. Now let us see what it looks like.
Sequential data is not independent and identically distributed.
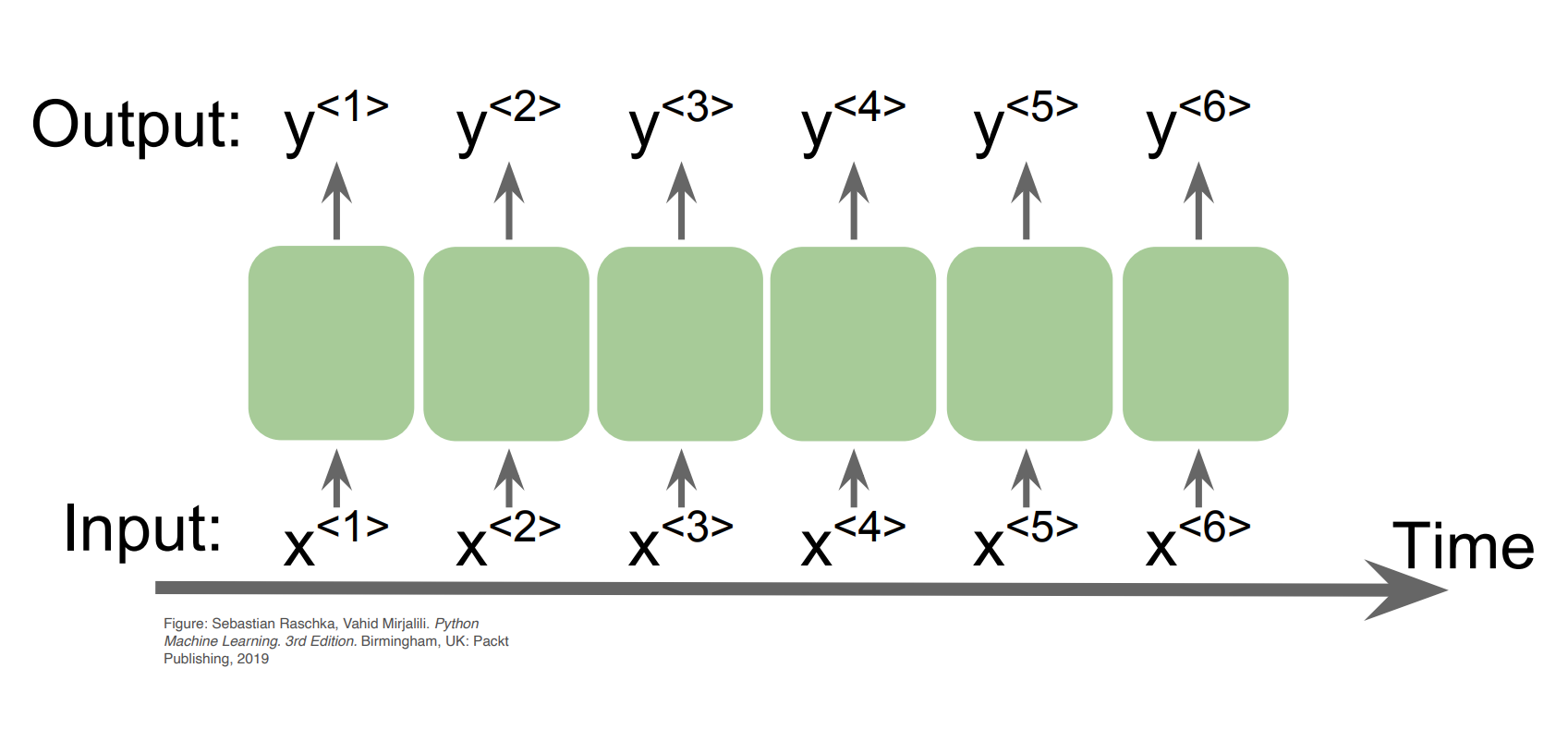
Fig. 24.1 sequential data#
And the RNNs use recurrent edge to update.
|
|
|---|---|
RNN1 (recurrent) |
RNN2 (unfolded RNN1) |
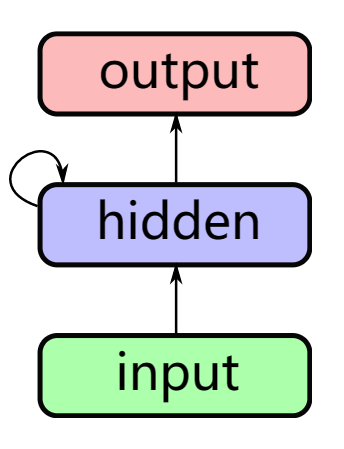
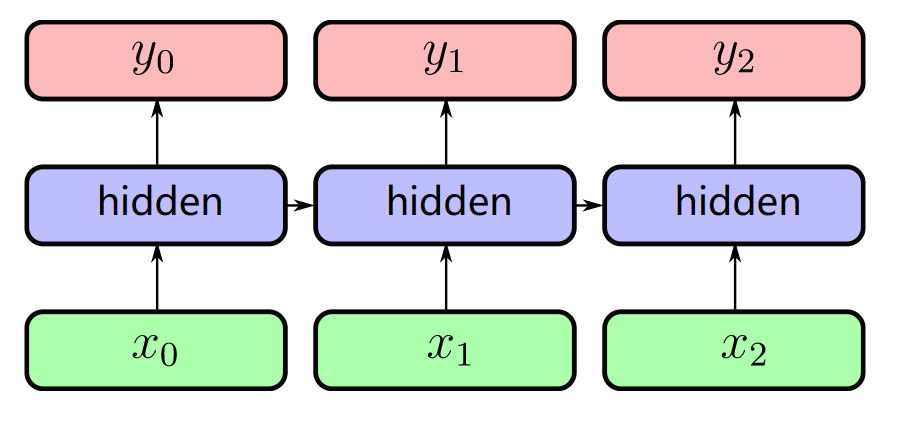
Then, the input (w0,w1,…,wt) sequence of words ( 1-hot encoded ) and the output (w1,w2,…,wt+1) shifted sequence of words ( 1-hot encoded ) have the following relation.
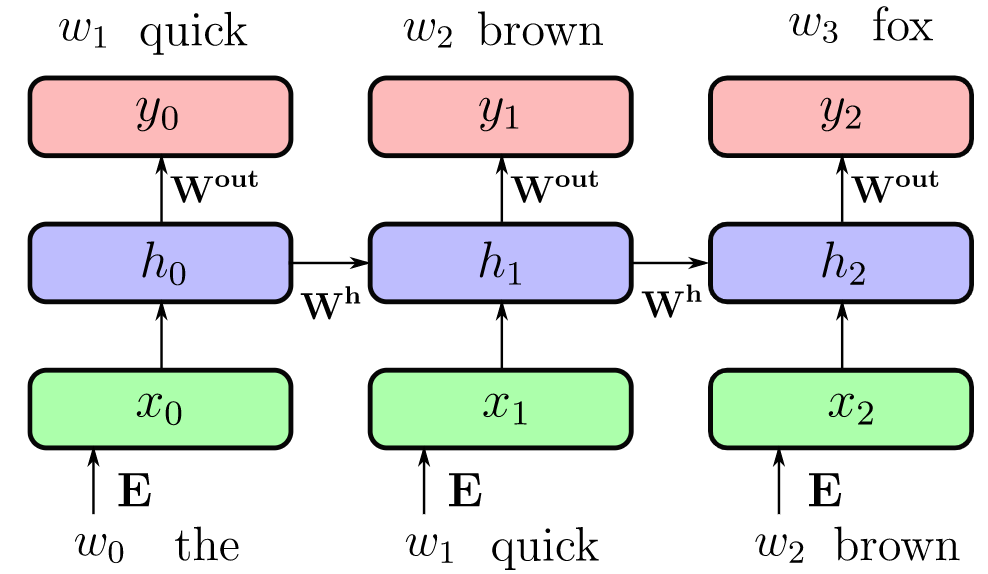
Fig. 24.2 RNN3#
The input projection is \(x_t = Emb(\omega_t) = E\omega_t\), the recurrent connection is \(h_t = g(W^h h_t + x_t + b^h)\), and the output projection should be \(y = softmax(W^o h_t + b^o)\). The backpropagation of RNN is in this way:
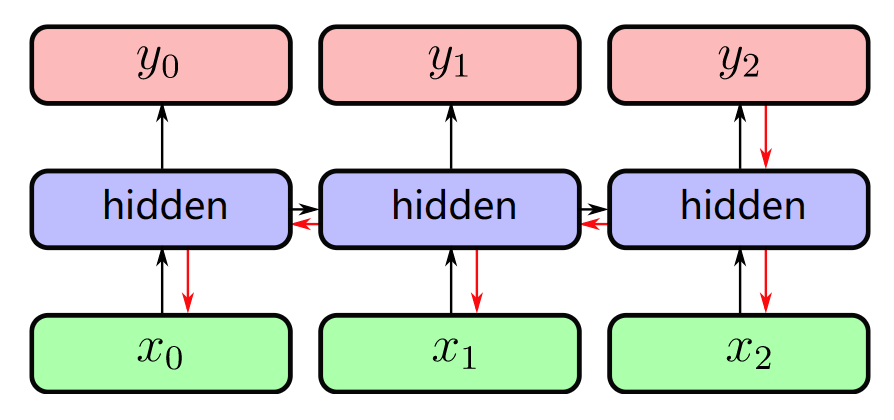
Fig. 24.3 RNN4#
Let’s make the backpropagation process more clearly.
First, we unfold a single-hidden layer RNN, and we can see the weight matrices \(W_h\) in it.
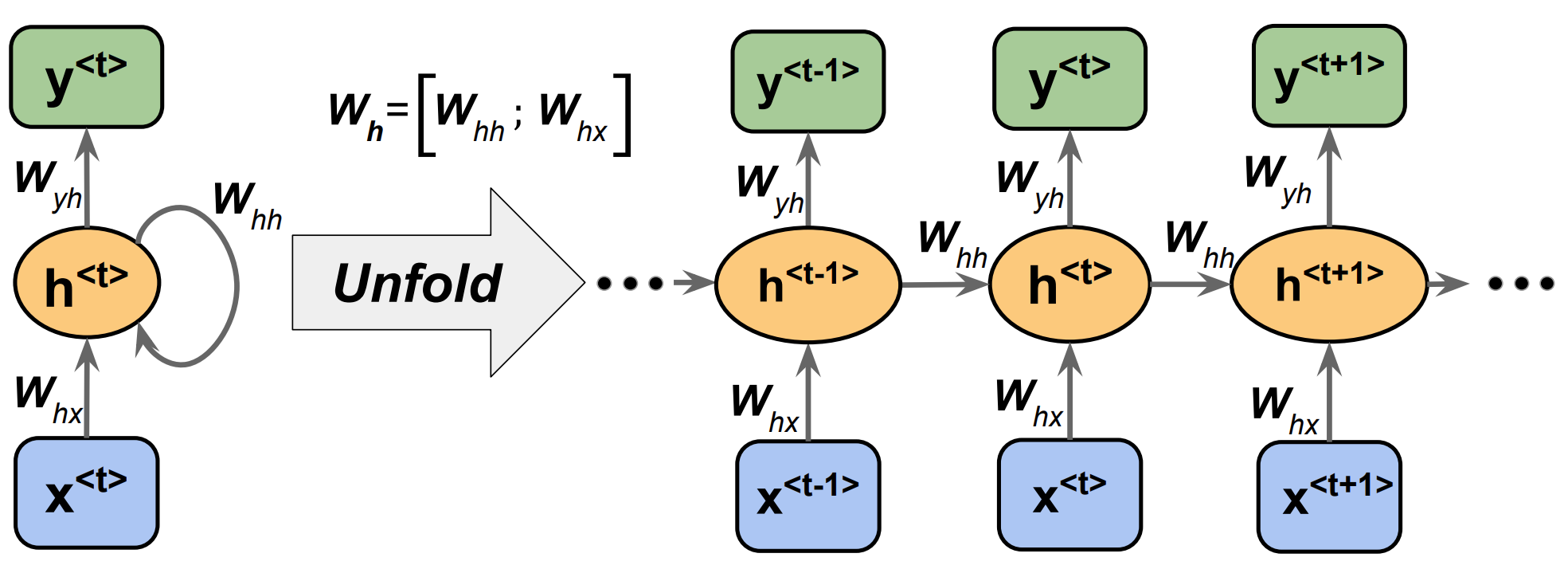
Fig. 24.4 backpropagation for RNN#
Through the image, we can get the output:
Net input: \(z_h^{<t>} = W_hx x^{<t>} + W_hh h^{<t-1>} + b_h\)
Activation: \(h^{<t>} = \sigma (z_h^{<t>})\)
Output: \(z_y^<t> = W_yh h^{<t>} + b_y\), \(y^{<t>} = \sigma(z_y^{<t>})\)
After that, the loss is computed as the sum over all time steps: \(L = \sum_{t=1}^T L^{<t>}\)
Note
There are some key points:
Similar as training very deep networks with tied parameters.
Example between \(x_0\) and \(y_2\): Wh is used twice.
Usually truncate the backprop after \(T\) timesteps.
Difficulties to train long-term dependencies.
24.1. Code#
A text classifier implemented in TensorFlow to classify SMS spam messages. Code first downloads and processes the SMS Spam Collection dataset from the UCI Machine Learning Repository and then builds a basic Recurrent neural network (RNN) for text classification using TensorFlow. The code first cleans and preprocesses the text, then splits it into training and test sets, followed by tokenizing and padding the training set. Next, the code uses an embedding layer to convert the tokenized text into a vector representation, which is then fed into a recurrent neural network and finally classified using a Softmax loss function. The output of the # code is the accuracy of the classifier along with some statistics We implement an RNN in TensorFlow to predict spam/ham from texts
import os
import re
import io
import requests
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from zipfile import ZipFile
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Set random seed for reproducibility
tf.random.set_seed(42)
# Download or open data
data_dir = "tmp"
data_file = "text_data.txt"
if not os.path.exists(data_dir):
os.makedirs(data_dir)
if not os.path.isfile(os.path.join(data_dir, data_file)):
zip_url = "http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip"
r = requests.get(zip_url)
z = ZipFile(io.BytesIO(r.content))
file = z.read("SMSSpamCollection")
# Format Data
text_data = file.decode()
text_data = text_data.encode("ascii", errors="ignore")
text_data = text_data.decode().split("\n")
# Save data to text file
with open(os.path.join(data_dir, data_file), "w") as file_conn:
for text in text_data:
file_conn.write("{}\n".format(text))
else:
# Open data from text file
text_data = []
with open(os.path.join(data_dir, data_file), "r") as file_conn:
for row in file_conn:
text_data.append(row)
text_data = text_data[:-1]
text_data = [x.split("\t") for x in text_data if len(x) >= 1]
[text_data_target, text_data_train] = [list(x) for x in zip(*text_data)]
# Create a text cleaning function
def clean_text(text_string):
text_string = re.sub(r"([^\s\w]|_|[0-9])+", "", text_string)
text_string = " ".join(text_string.split())
text_string = text_string.lower()
return text_string
# Clean texts
text_data_train = [clean_text(x) for x in text_data_train]
print(text_data_train[:5])
# Tokenize and pad sequences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(text_data_train)
text_processed = tokenizer.texts_to_sequences(text_data_train)
max_sequence_length = 25
text_processed = pad_sequences(
text_processed, maxlen=max_sequence_length, padding="post"
)
print(text_processed.shape)
['go until jurong point crazy available only in bugis n great world la e buffet cine there got amore wat', 'ok lar joking wif u oni', 'free entry in a wkly comp to win fa cup final tkts st may text fa to to receive entry questionstd txt ratetcs apply overs', 'u dun say so early hor u c already then say', 'nah i dont think he goes to usf he lives around here though']
(5574, 25)
# Shuffle and split data
text_processed = np.array(text_processed)
text_data_target = np.array([1 if x == "ham" else 0 for x in text_data_target])
shuffled_ix = np.random.permutation(np.arange(len(text_data_target)))
x_shuffled = text_processed[shuffled_ix]
y_shuffled = text_data_target[shuffled_ix]
# Split train/test set
ix_cutoff = int(len(y_shuffled) * 0.80)
x_train, x_test = x_shuffled[:ix_cutoff], x_shuffled[ix_cutoff:]
y_train, y_test = y_shuffled[:ix_cutoff], y_shuffled[ix_cutoff:]
vocab_size = len(tokenizer.word_index) + 1
print("Vocabulary Size: {:d}".format(vocab_size))
print("80-20 Train Test split: {:d} -- {:d}".format(len(y_train), len(y_test)))
Vocabulary Size: 8630
80-20 Train Test split: 4459 -- 1115
# Create the model using the Sequential API
embedding_size = 50
model = tf.keras.Sequential(
[
tf.keras.layers.Embedding(
input_dim=vocab_size,
output_dim=embedding_size,
input_length=max_sequence_length,
),
tf.keras.layers.SimpleRNN(units=10),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=2, activation="softmax"),
]
)
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.0005),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
# Train the model
epochs = 20
batch_size = 250
history = model.fit(
x_train, y_train, epochs=epochs, batch_size=batch_size, validation_split=0.2
)
Epoch 1/20
15/15 [==============================] - 3s 65ms/step - loss: 0.5753 - accuracy: 0.7575 - val_loss: 0.4707 - val_accuracy: 0.8756
Epoch 2/20
15/15 [==============================] - 0s 33ms/step - loss: 0.4656 - accuracy: 0.8433 - val_loss: 0.3906 - val_accuracy: 0.9283
Epoch 3/20
15/15 [==============================] - 0s 24ms/step - loss: 0.3762 - accuracy: 0.9162 - val_loss: 0.3093 - val_accuracy: 0.9574
Epoch 4/20
15/15 [==============================] - 0s 9ms/step - loss: 0.3103 - accuracy: 0.9422 - val_loss: 0.2595 - val_accuracy: 0.9652
Epoch 5/20
15/15 [==============================] - 0s 10ms/step - loss: 0.2693 - accuracy: 0.9498 - val_loss: 0.2225 - val_accuracy: 0.9664
Epoch 6/20
15/15 [==============================] - 0s 10ms/step - loss: 0.2285 - accuracy: 0.9686 - val_loss: 0.1987 - val_accuracy: 0.9664
Epoch 7/20
15/15 [==============================] - 0s 10ms/step - loss: 0.2024 - accuracy: 0.9795 - val_loss: 0.1820 - val_accuracy: 0.9619
Epoch 8/20
15/15 [==============================] - 0s 10ms/step - loss: 0.1825 - accuracy: 0.9748 - val_loss: 0.1675 - val_accuracy: 0.9630
Epoch 9/20
15/15 [==============================] - 0s 9ms/step - loss: 0.1647 - accuracy: 0.9821 - val_loss: 0.1631 - val_accuracy: 0.9608
Epoch 10/20
15/15 [==============================] - 0s 14ms/step - loss: 0.1546 - accuracy: 0.9837 - val_loss: 0.1623 - val_accuracy: 0.9574
Epoch 11/20
15/15 [==============================] - 0s 12ms/step - loss: 0.1400 - accuracy: 0.9865 - val_loss: 0.1622 - val_accuracy: 0.9552
Epoch 12/20
15/15 [==============================] - 0s 13ms/step - loss: 0.1302 - accuracy: 0.9868 - val_loss: 0.1632 - val_accuracy: 0.9552
Epoch 13/20
15/15 [==============================] - 0s 14ms/step - loss: 0.1285 - accuracy: 0.9865 - val_loss: 0.1640 - val_accuracy: 0.9540
Epoch 14/20
15/15 [==============================] - 0s 17ms/step - loss: 0.1194 - accuracy: 0.9871 - val_loss: 0.1579 - val_accuracy: 0.9552
Epoch 15/20
15/15 [==============================] - 0s 15ms/step - loss: 0.1190 - accuracy: 0.9874 - val_loss: 0.1647 - val_accuracy: 0.9518
Epoch 16/20
15/15 [==============================] - 0s 17ms/step - loss: 0.1103 - accuracy: 0.9874 - val_loss: 0.1596 - val_accuracy: 0.9563
Epoch 17/20
15/15 [==============================] - 0s 11ms/step - loss: 0.1033 - accuracy: 0.9879 - val_loss: 0.1530 - val_accuracy: 0.9585
Epoch 18/20
15/15 [==============================] - 0s 11ms/step - loss: 0.0954 - accuracy: 0.9905 - val_loss: 0.1611 - val_accuracy: 0.9552
Epoch 19/20
15/15 [==============================] - 0s 17ms/step - loss: 0.0937 - accuracy: 0.9896 - val_loss: 0.1640 - val_accuracy: 0.9552
Epoch 20/20
15/15 [==============================] - 0s 10ms/step - loss: 0.0924 - accuracy: 0.9907 - val_loss: 0.1848 - val_accuracy: 0.9484
# Plot loss and accuracy over time
plt.plot(history.history["loss"], label="Train Set")
plt.plot(history.history["val_loss"], label="Validation Set")
plt.title("Softmax Loss")
plt.xlabel("Epochs")
plt.ylabel("Softmax Loss")
plt.legend(loc="upper left")
plt.show()
plt.plot(history.history["accuracy"], label="Train Set")
plt.plot(history.history["val_accuracy"], label="Validation Set")
plt.title("Test Accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(loc="upper left")
plt.show()
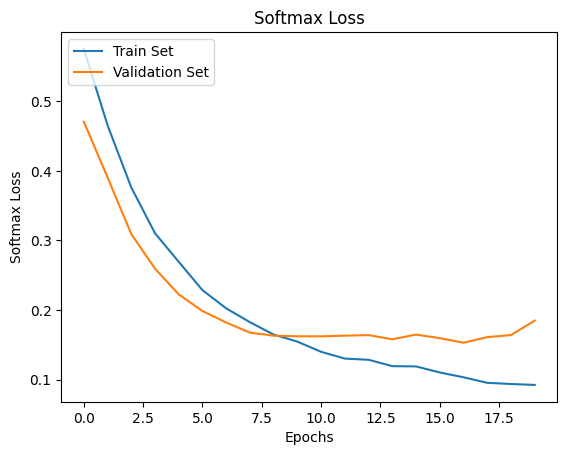
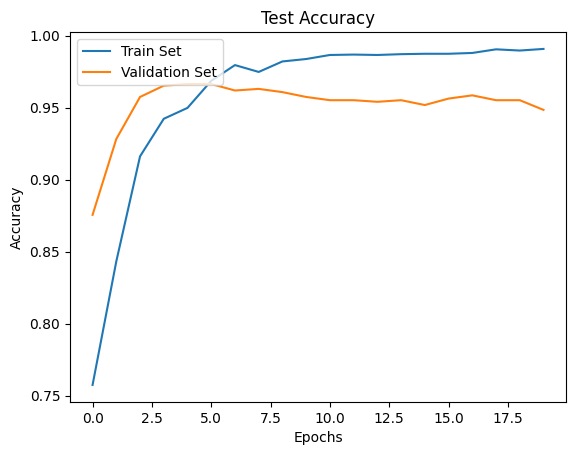
24.2. Your turn! 🚀#
You can practice your rnn skills by following the assignment google stock price prediction rnn
24.3. Acknowledgments#
Thanks to Nick for creating the open-source course tensorflow_cookbook and Sebastian Raschka for creating the open-sourse stat453-deep-learning-ss20. It inspires the majority of the content in this chapter.