Deep Q-learning
Contents
# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet pandas scikit-learn numpy matplotlib jupyterlab_myst ipython
33. Deep Q-learning#
33.1. Overview#
Usually, we regard Deep Q Network as DQN, and it can also be called Reinforcement Learning (RL) whose aim is to achieve the desired behavior of an agent that learns from its mistakes and improves its performance.
RL is a type of machine learning that allows us to create AI agents that learn from the environment by interacting with it to maximize its cumulative reward. Here is an image showing the basic RL operation principle:
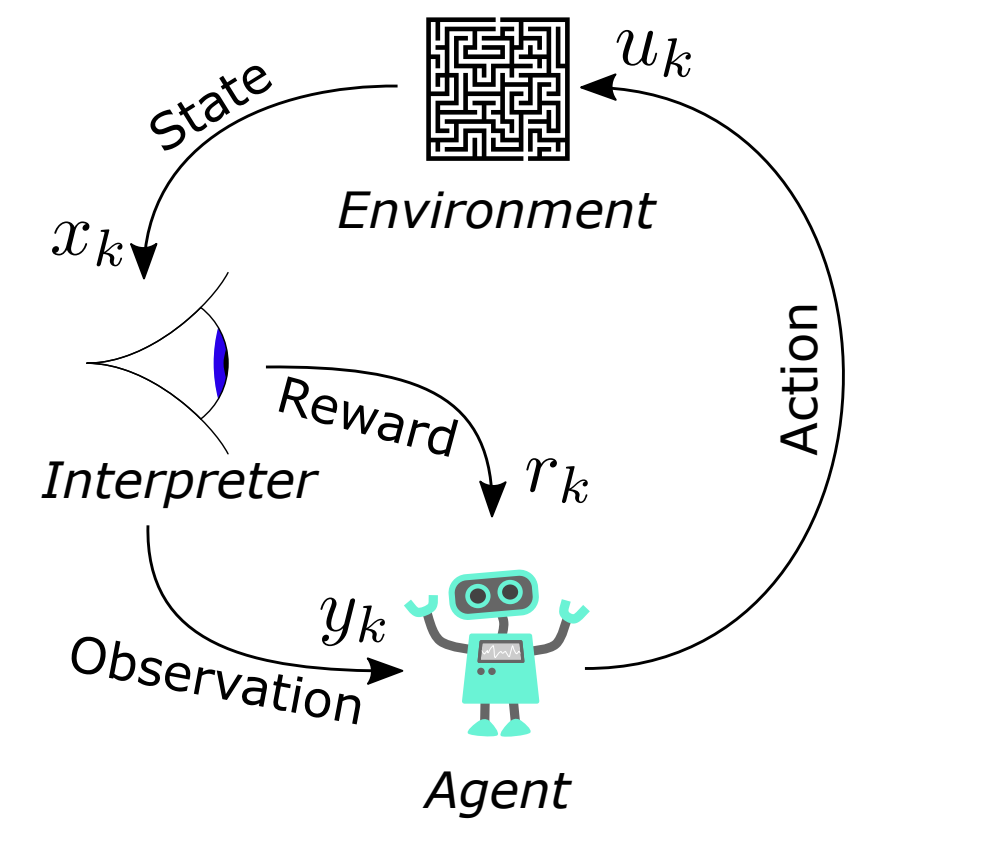
Fig. 33.1 Pipline of DQN#
From this image, we can see that at each step \(k\), the agent picks an action \(u_k\), receives an observation \(y_k\) and receives a reward \(r_k\), and the environment receives an action \(u_k\), emits an observation \(y_{k+1}\) and emits a reward \(r_{k+1}\). Later, the time increments k ← k + 1. A one step time delay is assumed between executing the action and receiving the observation as well as reward. We assume that the resulting time interval \(∆t = t_k − t_{k+1}\) is constant.
Note
Key characteristics of RL:
No supervisor.
Data-driven.
Discrete time steps.
Sequential data stream (not independent and identically distributed data).
Agent actions affect subsequent data (sequential decision making).
33.2. Basic terminology#
33.2.1. Reward#
A reward is a scalar random variable \(R_k\) with realizations \(r_k\):
Often it is considered a real-number \(r_k \in \mathbb{R}\) or an integer \(r_k \in \mathbb{Z}\).
The reward function (interpreter) may be naturally given or is a design degree of freedom (i.e., can be manipulated).
It fully indicates how well an RL agent is doing at step \(k\).
The agent’s task is to maximize its reward over time.
Note
If we want the machine to flip a pancake:
Pos. reward: catching the 180◦ rotated pancake
Neg. reward: droping the pancake on the floor
Rewards can have many different flavors and are highly dependent on the given problem:
Actions may have short and/or long term consequences.
The reward for a certain action may be delayed.
Examples: Stock trading, strategic board games,…
Rewards can be positive and negative real values.
Certain situations (e.g. car hits wall) might lead to a negative reward.
Exogenous impacts might introduce stochastic reward components.
Example: A wind gust pushes the helicopter into a tree.
Besides, the RL agent’s learning process is heavily linked with the reward distribution over time. Designing expedient rewards functions is therefore crucially important for successfully applying RL. And often there is no predefined way on how to design the “best reward function”.
33.2.2. Task-dependent return definitions#
33.2.2.1. Episodic tasks#
Episodic tasks can naturally break into subsequences (finite horizon), for examples: most games, maze,… And the return becomes a finite sum: \(g_k = r_{k+1} + r_{k+2} + ... + r_{N}\). Episodes end at their terminal step \(k = N\).
33.2.2.2. Continuing tasks#
Continuing tasks lack a natural end (infinite horizon), for example: process control task, and the return should be discounted to prevent infinite numbers: \(g_k = r_{k+1} + \gamma r_{k+2} + \gamma^2 r_{k+3} + ... = \sum_{i=1}^{\infty} \gamma^{i} r_{k+i+1}\). Here, \(\gamma ∈ {\mathbb{R}|0 ≤ \gamma ≤ 1}\) is the discount rate.
Note
From numeric viewpoint: If \(\gamma\) = 1 and \(r_k\) > 0 for \(k → \infty \), \(g_k\) gets infinite. If \(\gamma\) < 1 and \(r_k\) is bounded for \(k → \infty\), \(g_k\) is bounded.
From strategic viewpoint: If \(\gamma\) ≈ 1: agent is farsighted. If \(\gamma\) ≈ 0: agent is shortsighted (only interested in immediate reward).
33.2.3. State#
33.2.3.1. Environment state#
Random variable \(X_k^{e}\) with realizations \(x_k^{e}\):
Internal status representation of the environment, e.g.physical states (car velocity or motor current), game states (current chess board situation). financial states (stock market status).
Fully, limited or not at all visible by the agent:sometimes even ’foggy’ or uncertain, but in general: \(Y_k = f(X_k)\) as the measurable outputs of the environment.
Continuous or discrete quantity.
33.2.3.2. Agent state#
Random variable \(X_k^{a}\) with realizations \(x_k^{a}\):
Internal status representation of the agent.
In general: \(x_k^{a} \neq x_k^{e}\), e.g., due to measurement noise or an additional agent’s memory.
Agent’s condensed information relevant for next action.
Dependent on internal knowledge / policy representation of the agent.
Continuous or discrete quantity.
33.2.4. Action#
An action is the agent’s degree of freedom in order to maximize its reward. The major distinctions are:
Finite action set (FAS): \(u_k ∈ {u_{k,1},u_{k,2}, ...} ∈ \mathbb{R}_m\).
Continuous action set (CAS): Infinite number of actions: \(u_k ∈ \mathbb{R}_m\).
Deterministic \(u_k\) or random Uk variable.
Often state-dependent and potentially constrained: \(u_k ∈ U(x_k) ⊆ \mathbb{R}_m\).
Note
Evaluating the state and action spaces (e.g., finite vs. continuous) of a new RL problem should be always the first steps in order to choose appropriate solution algorithms.
33.2.5. Policy#
A policy \(\pi\) is the agent’s internal strategy on picking actions.
Deterministic policies: maps state and action directly: \(u_k = \pi (x_k)\).
Stochastic policies: maps a probability of the action given a state: \(\pi(U_k|X_k) = \mathbb{P} [Uk|Xk]\) .
RL is all about changing \(\pi\) over time in order to maximize the expected return.
33.2.5.1. Example#
Here is a deterministic policy example: find optimal gains \({K_p, K_i, K_d}\) given the reward \(r_k = −e^2_k\)
Agent’s behavior is explicitly determined by \({K_p, K_i, K_d}\).
Reference value is part of the environment state: \(x_k =[y_k y^∗_k]^T\).
Control output is the agent’s action: \(u_k = \pi(x_k|K_p, K_i, K_d)\).
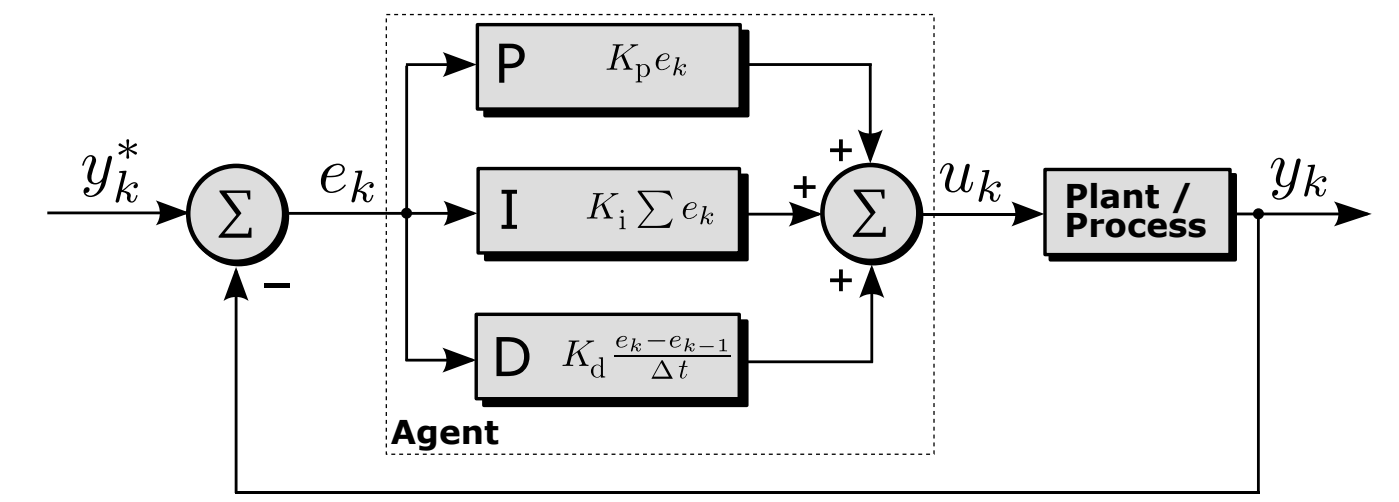
Fig. 33.2 Classical PID control loop with scalar quantities#
33.2.6. Value functions#
The state-value function is the expected return being in state \(x_k\) following a policy \(\pi:v_{\pi}(x_k)\).
Assuming an MDP problem structure the state-value function is \(v_{\pi}(x_k) = \mathbb{E}_{\pi} [G_k | X_k = x_k] = \mathbb{E}_{\pi}[\sum_{i=0}^{\infty} \gamma^i R_{k+i+1} | x_k]\).
The action-value function is the expected return being in state \(x_k\) taken an action \(u_k\) and, thereafter, following a policy \(\pi: q_{\pi}(x_k,u_k)\).
Assuming an MDP problem structure the action-value function is \(q_{\pi}(x_k, u_k) = \mathbb{E}_{\pi} [G_k | X_k=x_k, U_k=u_k] = \mathbb{E}_{\pi} [\sum_{i=0}^{\infty} \gamma^i R_{k+i+1} | x_k,u_k]\).
A key task in RL is to estimate \(v_{\pi}(x_k)\) and \(q_{\pi}(x_k,u_k)\) based on sampled data.
33.2.7. Model#
A model predicts what will happen inside an environment.
That could be a state model \(\mathcal{P}\): \(\mathcal{P} = \mathbb{P}[X_{k+1}=x_{k+1}|X_k=x_k, U_k=u_k]\). Or a reward model \(\mathcal{R}\): \(\mathcal{R} = \mathbb{P}[R_{k+1}=r_{k+1}|X_k=x_k, U_k=u_k]\). In general, those models could be stochastic (as denoted above) but in some problems relax to a deterministic form. Using data in order to fit a model is a learning problem of its own and often called system identification.
33.2.8. Exploration and exploitation#
In RL the environment is initially unknown. How to act optimal?
Exploration: find out more about the environment.
Exploitation: maximize current reward using limited information.
Note
Trade-off problem: what’s the best split between both strategies?
33.3. Main algorithms#
In this section, we will take maze as an example. The problem statement is:
Reward: \(r_k = −1\).
At goal: episode termination.
Actions: \(u_k \in {N, E, S, W}\).
State: agent’s location.
Deterministic problem (no stochastic influences).
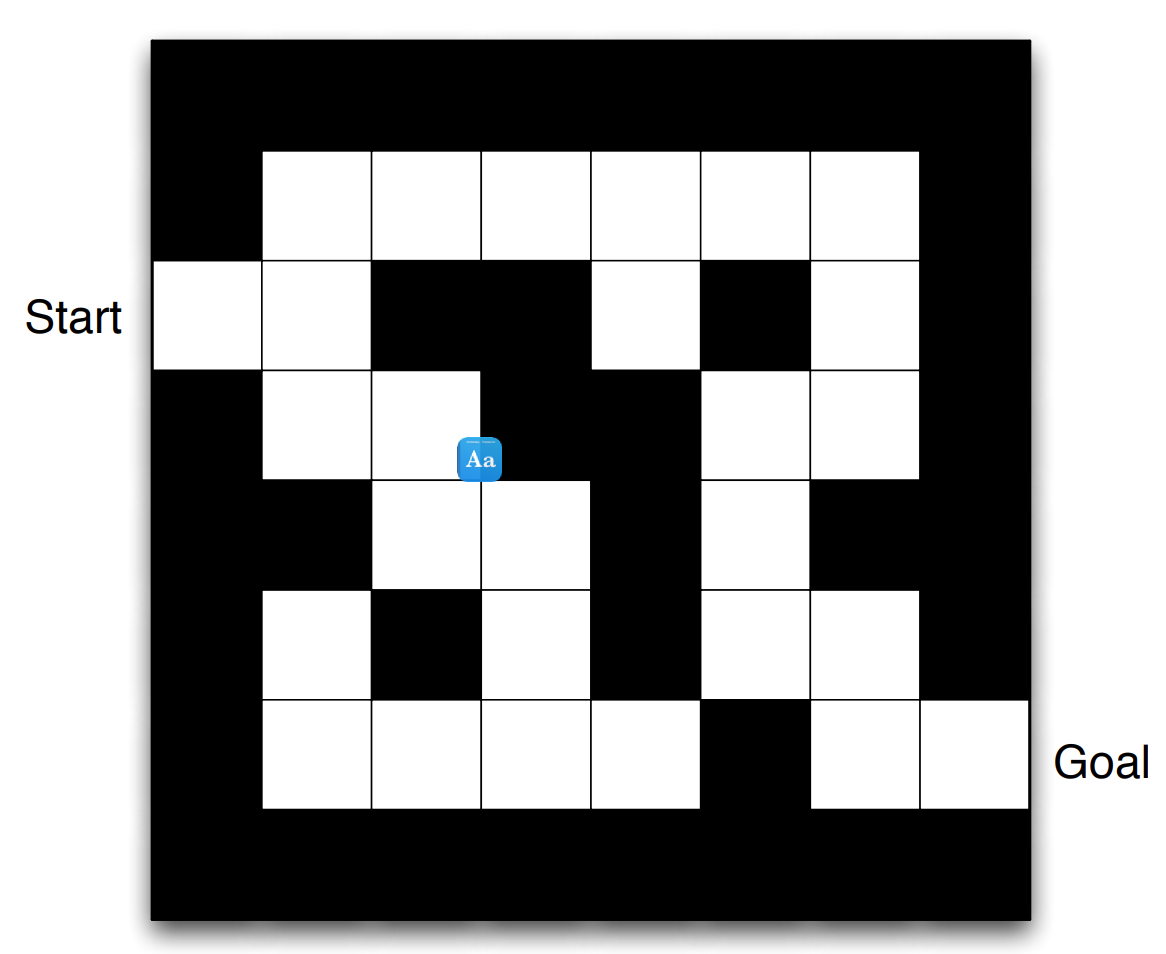
Fig. 33.3 Maze setup statement#
33.3.1. RL-solution by policy#
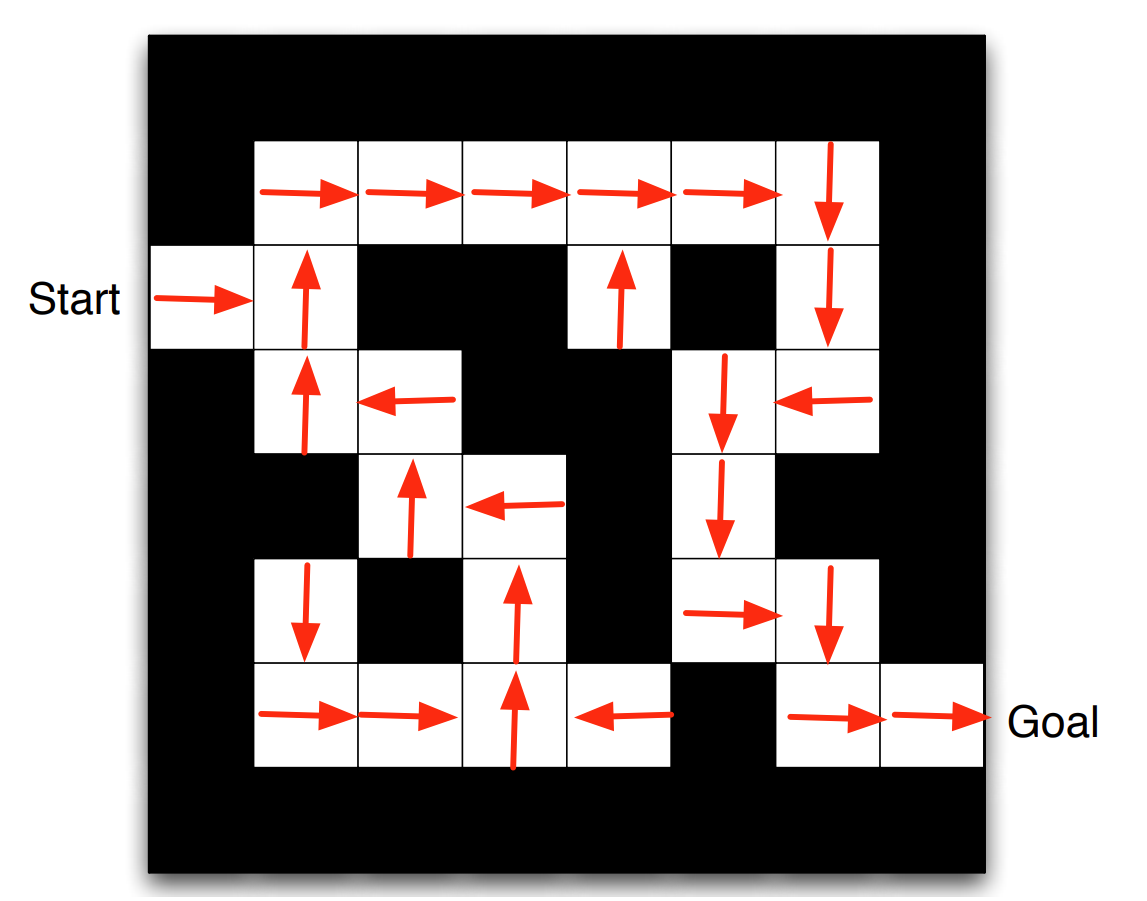
Fig. 33.4 Maze solved by policy#
Key characteristics:
For any state there is a direct action command.
The policy is explicitly available.
33.3.2. RL-solution by value function#

Fig. 33.5 Maze solved by value function#
Key characteristics:
The agent evaluates neighboring maze positions by their value.
The policy is only implicitly available.
33.3.3. RL-solution by model evaluation#

Fig. 33.6 Maze solved by model evaluation#
Key characteristics:
Agent uses internal model of the environment.
The model is only an estimate (inaccurate, incomplete).
The agent interacts with the model before.
33.3.4. RL agent taxonomy#
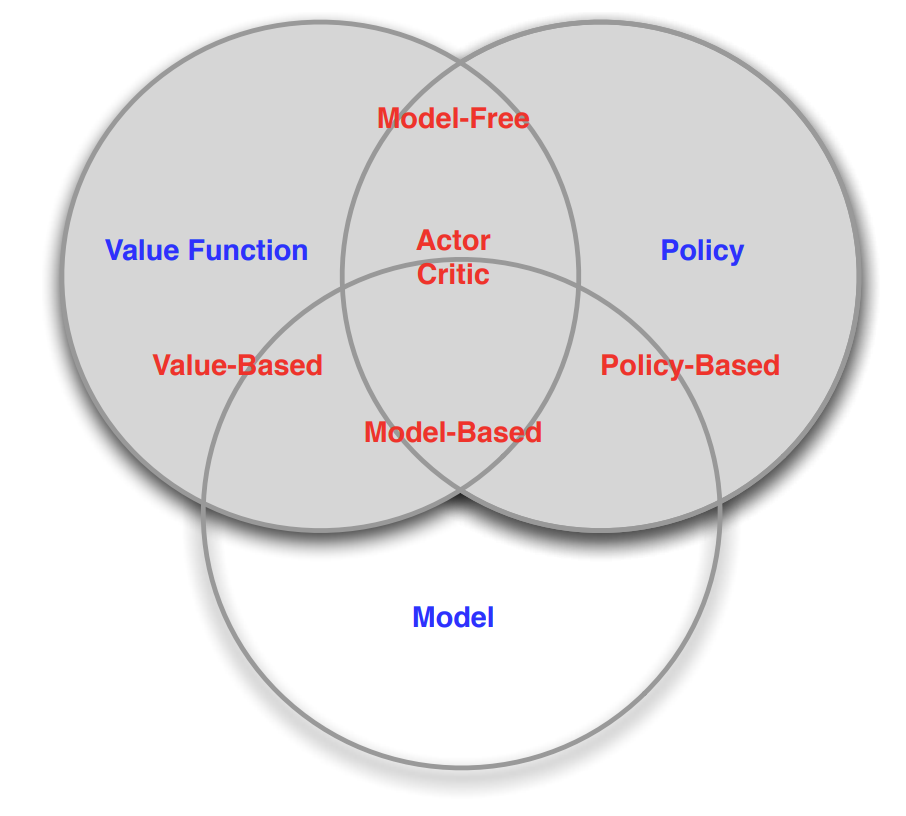
Fig. 33.7 Main categories of reinforcement learning algorithms#
33.4. Code#
This is an example of DQN discrete model.
import tensorflow as tf
import random as r
import numpy as np
import matplotlib.pyplot as plt
class NeuralNetwork:
def __init__(self, input_size, num_memory_units):
self.model = self.create_model(input_size, num_memory_units)
def create_model(self, input_size, num_memory_units):
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(6, activation='sigmoid', input_shape=(input_size,)),
tf.keras.layers.Dense(6, activation='sigmoid'),
tf.keras.layers.Dense(4 + num_memory_units)
])
return model
def predict(self, inputs):
return self.model(inputs, training=True)
class Maze:
def __init__(self, maze_type):
# Use the maze types from maze_collection.py
[self.maze,
[self.startX, self.startY],
[self.goalX, self.goalY]] = maze_type
self.x = self.startX
self.y = self.startY
self.won = False
self.win = None
self.squares = None
def reset(self):
self.x = self.startX
self.y = self.startY
self.won = False
if self.win is not None:
self.display()
def display_commandline(self):
to_print = ""
for y_pos, y in enumerate(self.maze):
for x_pos, x in enumerate(y):
if self.x == x_pos and self.y == y_pos:
to_print += " O "
elif self.goalX == x_pos and self.goalY == y_pos:
to_print += " X "
elif x == 0:
to_print += " "
elif x == 1:
to_print += " # "
to_print += "\n"
print(to_print)
# def initialise_graphics(self):
# self.win = g.GraphWin("Maze", 200 + (50 * len(self.maze[0])), 200 + (50 * len(self.maze)))
# self.squares = []
# for i in range(len(self.maze)):
# self.squares.append([])
# for j in range(len(self.maze[i])):
# self.squares[i].append(
# g.Rectangle(g.Point(100 + (j * 50), 100 + (i * 50)), g.Point(150 + (j * 50), 150 + (i * 50))))
# self.squares[i][j].draw(self.win)
# self.display()
def display(self):
for y_pos, y in enumerate(self.maze):
for x_pos, x in enumerate(y):
if self.x == x_pos and self.y == y_pos:
self.squares[y_pos][x_pos].setFill("orangered")
elif self.goalX == x_pos and self.goalY == y_pos:
self.squares[y_pos][x_pos].setFill("green")
elif x == 0:
self.squares[y_pos][x_pos].setFill("white")
elif x == 1:
self.squares[y_pos][x_pos].setFill("black")
def check_win_condition(self):
if self.x == self.goalX and self.y == self.goalY:
self.won = True
def move_up(self):
if self.y - 1 >= 0 and self.maze[self.y - 1][self.x] != 1:
self.y -= 1
self.check_win_condition()
def move_down(self):
if self.y + 1 < len(self.maze) and self.maze[self.y + 1][self.x] != 1:
self.y += 1
self.check_win_condition()
def move_left(self):
if self.x - 1 >= 0 and self.maze[self.y][self.x - 1] != 1:
self.x -= 1
self.check_win_condition()
def move_right(self):
if self.x + 1 < len(self.maze[0]) and self.maze[self.y][self.x + 1] != 1:
self.x += 1
self.check_win_condition()
def distance_up(self):
for i in range(self.y, -1, -1):
if i - 1 < 0 or self.maze[i - 1][self.x] == 1:
return self.y - i
def distance_down(self):
for i in range(self.y, len(self.maze), 1):
if i + 1 >= len(self.maze) or self.maze[i + 1][self.x] == 1:
return i - self.y
def distance_left(self):
for i in range(self.x, -1, -1):
if i - 1 < 0 or self.maze[self.y][i - 1] == 1:
return self.x - i
def distance_right(self):
for i in range(self.x, len(self.maze[0]), 1):
if i + 1 >= len(self.maze) or self.maze[self.y][i + 1] == 1:
return i - self.x
def normal_x(self):
return self.x / (len(self.maze[0]) - 1)
def normal_y(self):
return self.y / (len(self.maze) - 1)
def normal_goal_x(self):
return self.goalX / (len(self.maze[0]) - 1)
def normal_goal_y(self):
return self.goalY / (len(self.maze) - 1)
T_maze = [
[ # Layout
[0, 0, 0],
[1, 0, 1],
[1, 0, 1]
],
[1, 2], # Start coordinates
[0, 0] # Goal coordinates
]
def main(output_file_name):
# housekeeping
m = Maze(T_maze)
learning_rate = 0.0001
num_memory_units = 4
graphical = True
file_output = True
nn = NeuralNetwork(2 + num_memory_units, num_memory_units)
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate)
if file_output is True:
# output to file (this is set to overwrite!)
file = open(output_file_name + ".txt", "w")
file.write("Iter\tWon?\tSteps\tAll steps\n")
# weight update operation
# ph_delta_weights_list = [tf.placeholder(tf.float32, w.get_shape()) for w in weights_list]
# ph_delta_weights_list = [w.get_shape() for w in weights_list]
# update_weights = [tf.compat.v1.assign(weights_list[i], weights_list[i] + ph_delta_weights_list[i])
# for i in range(len(weights_list))]
# training setup
maxSteps = 20
iteration = 0
maxIterations = 10000
steps_taken = np.zeros(maxIterations)
# Plot display -----------------------------------------------------------------------------------------------------
if graphical is True:
spread = 50
plt.ion()
fig = plt.figure("Maze solver")
ax = fig.add_subplot(111)
ax.axis([0, maxIterations/spread + 1, 0, maxSteps + 1])
plt.ylabel("Steps taken")
plt.xlabel("Iterations ({})".format(spread))
ax.plot([0], [0])
ax.grid()
iterations = []
duration_history = []
# Looping through iterations
while iteration < maxIterations:
with tf.GradientTape() as tape:
y = nn.predict(tf.convert_to_tensor([input_values], dtype=tf.float32))
left_output = y[:, 0:4]
right_output = y[:, 4:]
action_probs = tf.nn.softmax(left_output)
memory_units = tf.sigmoid(right_output)
action = np.random.choice(4, p=action_probs[0].numpy())
if action == 0:
m.move_up()
dp_dthetas.append(tape.gradient(action_probs[0, 0], nn.model.trainable_variables))
elif action == 1:
m.move_right()
dp_dthetas.append(tape.gradient(action_probs[0, 1], nn.model.trainable_variables))
elif action == 2:
m.move_down()
dp_dthetas.append(tape.gradient(action_probs[0, 2], nn.model.trainable_variables))
else:
m.move_left()
dp_dthetas.append(tape.gradient(action_probs[0, 3], nn.model.trainable_variables))
for i in range(step):
grads = dp_dthetas[i]
delta = [(learning_rate * (1 / action_probs[0, action].numpy()) * reward) * grad for grad in grads]
optimizer.apply_gradients(zip(delta, nn.model.trainable_variables))
# Current step
step = 0
# # All outputs and dp_dthetas for this iteration
# probabilities = np.zeros(maxSteps)
# dp_dthetas = list()
#
# memory = np.zeros(num_memory_units)
#
# movements = ""
while m.won is False and step < maxSteps:
# All outputs and dp_dthetas for this iteration
probabilities = np.zeros(maxSteps)
dp_dthetas = list()
memory = np.zeros(num_memory_units)
movements = ""
# Defining neural network input
input_values = np.array([m.normal_x(), m.normal_y()])
input_values = np.append(input_values, memory)
# Running input through the neural network
# [output, dp0dtheta, dp1dtheta, dp2dtheta, dp3dtheta, output_memory] =\
# sess.run([y, dprobability0_dweights, dprobability1_dweights, dprobability2_dweights,
# dprobability3_dweights, memory_units],
# feed_dict={x: [input_values]})
with tf.GradientTape(persistent=True) as tape:
x = tf.cast(input_values, tf.float32)
W1 = tf.Variable(tf.random.truncated_normal([2+num_memory_units, 6]))
b1 = tf.Variable(tf.random.truncated_normal([1, 6]))
W2 = tf.Variable(tf.random.truncated_normal([6, 6]))
b2 = tf.Variable(tf.random.truncated_normal([1, 6]))
W3 = tf.Variable(tf.random.truncated_normal([6, 4+num_memory_units]))
b3 = tf.Variable(tf.random.truncated_normal([1, 4+num_memory_units]))
h1 = tf.sigmoid(tf.matmul([x], W1) + b1)
h2 = tf.sigmoid(tf.matmul(h1, W2) + b2)
output_final_layer_before_activation_function = tf.matmul(h2, W3) + b3
left_output = output_final_layer_before_activation_function[:, 0:4]
right_output = output_final_layer_before_activation_function[:, 4:]
y = tf.nn.softmax(left_output)
memory_units = tf.sigmoid(right_output)
weights_list = [W1, b1, W2, b2, W3, b3]
dprobability0_dweights = tape.gradient(y[:, 0], weights_list)
# print(dprobability0_dweights)
# print("gradient")
dprobability1_dweights = tape.gradient(y[:, 1], weights_list)
dprobability2_dweights = tape.gradient(y[:, 2], weights_list)
dprobability3_dweights = tape.gradient(y[:, 3], weights_list)
ph_delta_weights_list = [w.get_shape() for w in weights_list]
# update_weights = [tf.compat.v1.assign(weights_list[i], weights_list[i] + ph_delta_weights_list[i])
# for i in range(len(weights_list))]
[output, dp0dtheta, dp1dtheta, dp2dtheta, dp3dtheta, output_memory] =\
[y, dprobability0_dweights, dprobability1_dweights, dprobability2_dweights,
dprobability3_dweights, memory_units]
# Random value between 0 and 1, inclusive on both sides
result = r.uniform(0, 1)
if result <= output[0][0]:
# Up
m.move_up()
probabilities[step] = output[0][0]
dp_dthetas.append(dp0dtheta)
print(dp0dtheta)
print("=========================================")
movements += "U"
elif result <= output[0][0] + output[0][1]:
# Right
m.move_right()
probabilities[step] = output[0][1]
dp_dthetas.append(dp1dtheta)
movements += "R"
elif result <= output[0][0] + output[0][1] + output[0][2]:
# Down
m.move_down()
probabilities[step] = output[0][2]
dp_dthetas.append(dp2dtheta)
movements += "D"
elif result <= output[0][0] + output[0][1] + output[0][2] + output[0][3]:
# Left
m.move_left()
probabilities[step] = output[0][3]
dp_dthetas.append(dp3dtheta)
movements += "L"
memory = output_memory[0]
step += 1
print("Iteration #{:05d}\tWon: {}\tSteps taken: {:04d}\tSteps: {}".format(iteration, m.won,
step, movements))
if file_output is True:
file.write("{:05d}\t{}\t{:04d}\t{}\n".format(iteration, m.won, step, movements))
# Assigning a reward
reward = maxSteps - (2 * step) # linear reward function
#reward = maxSteps - pow(step, 2) # power reward function
# Applying weight change for every step taken, based on the reward given at the end
for i in range(step):
# print(dp_dthetas[0][0])
# print('===================================')
# print((1 / probabilities[i]) * reward)
deltaTheta = [(learning_rate * (1 / probabilities[i]) * reward) * dp_dthetas[i][j]
for j in range(len(weights_list))]
# sess.run(update_weights, feed_dict=dict(zip(ph_delta_weights_list, deltaTheta)))
update_weights = [tf.compat.v1.assign(weights_list[i], weights_list[i] + ph_delta_weights_list[i])
for i in range(len(dict(zip(ph_delta_weights_list, deltaTheta))))]
steps_taken[iteration] = step
if graphical is True and iteration % spread == 0:
steps_mean = np.mean(steps_taken[iteration-spread:iteration+1])
iterations = iterations+[iteration/spread]
duration_history = duration_history+[steps_mean]
del ax.lines[0]
ax.plot(iterations, duration_history, 'b-', label='Traj1')
plt.draw()
plt.pause(0.001)
m.reset()
iteration += 1
if file_output is True:
file.close()
if graphical is True:
if file_output is True:
plt.savefig(output_file_name + ".png")
else:
plt.show()
#input("Press [enter] to continue.")
plt.close()
import os
import tensorflow as tf
# Ensure we are using TensorFlow 2.x
if not tf.__version__.startswith('2'):
raise ValueError('This code requires TensorFlow V2.x')
def main(directory_name):
# Sample TensorFlow operation for demonstration
# This creates a constant tensor and prints it.
tensor = tf.constant([[1, 2], [3, 4]])
print(f"In directory: {directory_name}, tensor values are:")
print(tensor)
if __name__ == "__main__":
for run in range(11, 25):
number = "{:05d}".format(run)
dir_name = "T_fixed-memory-linear_reward_" + number
# Check if directory exists, if not create it
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# Execute main function
main(dir_name)
In directory: T_fixed-memory-linear_reward_00011, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00012, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00013, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00014, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00015, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00016, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00017, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00018, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00019, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00020, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00021, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00022, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00023, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
In directory: T_fixed-memory-linear_reward_00024, tensor values are:
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
33.5. Your turn! 🚀#
Assignment - DQN on foreign exchange market
33.6. Self study#
You can refer to this website for further study:
33.7. Acknowledgments#
Thanks to Paderborn University - LEA for creating the open-source course reinforcement_learning_course_materials and Gergely Pacsuta for creating the open-source project tf-nn-maze-solver. They inspire the majority of the content in this chapter.